




Next: Step-length Definition
Up: Review of Frequency-domain waveform
Previous: Gradient Vector Definition
The use of conjugate gradients helps to speed convergence by choosing a direction that is a linear combination of the past and current steepest descent vectors Luenberger (1984). Following Mora (1987), I use a conjugate gradient approach given by Polak and Ribiére (1969)
| 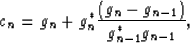 |
(10) |
where cn is the conjugate gradient update. Note that this is equivalent to the formulation in Mora (1987) where data and model space covariances are represented by identity operators. Equation 5 thus modifies to
| 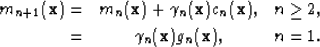 |
|
| (11) |
The computation of conjugate gradient direction in equation 11 comes essentially at no cost because the previous gradient vector, gn-1, easily can be stored in memory.
Next: Step-length Definition
Up: Review of Frequency-domain waveform
Previous: Gradient Vector Definition
Stanford Exploration Project
1/16/2007