Next: Multidimensional recursive filter preconditioning
Up: One-dimensional synthetic examples
Previous: One-dimensional synthetic examples
One of the factors affecting the convergence of iterative data
regularization is clustering of data points in the output bins. Since
least-squares optimization assigns equal weight to each data point, it
may apply inadequate effort to fit a cluster of data points with
similar values in a particular output bin. To avoid this problem, we
can replace the regularized optimization with a less accurate but more
efficient two-step approach: data binning followed by missing data
interpolation.
Missing data interpolation is a particular case of data
regularization, where the input data are already given on a regular
grid, and we need to reconstruct only the missing values in empty
bins. Claerbout (1992) formulates the basic
principle of missing data interpolation as follows:
A method for restoring missing data is to ensure that the restored
data, after specified filtering, has minimum energy.
Mathematically, this principle can be expressed by the simple
equation
| 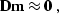 |
(73) |
where 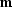 is the data vector and
is the data vector and 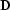 is the specified
filter. Equation (
is the specified
filter. Equation (![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) ) is completely equivalent to
equation (). The approximate equality sign means that
equation () is solved by minimizing the squared norm
(the power) of its left side. Additionally, the known data values
must be preserved in the optimization scheme. Introducing the mask
operator
) is completely equivalent to
equation (). The approximate equality sign means that
equation () is solved by minimizing the squared norm
(the power) of its left side. Additionally, the known data values
must be preserved in the optimization scheme. Introducing the mask
operator 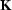 , which can be considered as a diagonal matrix with
zeros at the missing data locations and ones elsewhere, we can rewrite
equation () in the extended form
, which can be considered as a diagonal matrix with
zeros at the missing data locations and ones elsewhere, we can rewrite
equation () in the extended form
| 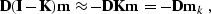 |
(74) |
in which 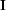 is the identity operator, and
is the identity operator, and 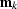 represents the known portion of the data. It is important to note that
equation () corresponds to the limiting case of the
regularized linear system
represents the known portion of the data. It is important to note that
equation () corresponds to the limiting case of the
regularized linear system
| 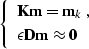 |
(75) |
for the scaling coefficient  approaching zero.
System () is equivalent to
system (-) with the masking
operator playing the role of the forward interpolation
operator
approaching zero.
System () is equivalent to
system (-) with the masking
operator playing the role of the forward interpolation
operator 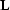 . Setting to zero implies putting far
more weight on the first equation in () and using the
second equation only to constrain the null space of the solution.
Applying the general theory of data-space regularization from
Chapter , we can immediately transform system
() to the equation
. Setting to zero implies putting far
more weight on the first equation in () and using the
second equation only to constrain the null space of the solution.
Applying the general theory of data-space regularization from
Chapter , we can immediately transform system
() to the equation
| 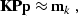 |
(76) |
where 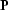 is a preconditioning operator, and
is a preconditioning operator, and 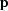 is the
preconditioning variable, connected with by the simple
relationship
is the
preconditioning variable, connected with by the simple
relationship
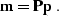
According to equations () and () from
Chapter , equations () and
() have exactly the same solutions if the following
condition is satisfied:
| 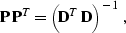 |
(77) |
where we need to assume the self-adjoint operator
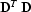 to be invertible. If is represented
by a discrete convolution, the natural choice for is the
corresponding deconvolution (inverse recursive filtering) operator:
to be invertible. If is represented
by a discrete convolution, the natural choice for is the
corresponding deconvolution (inverse recursive filtering) operator:
| 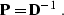 |
(78) |
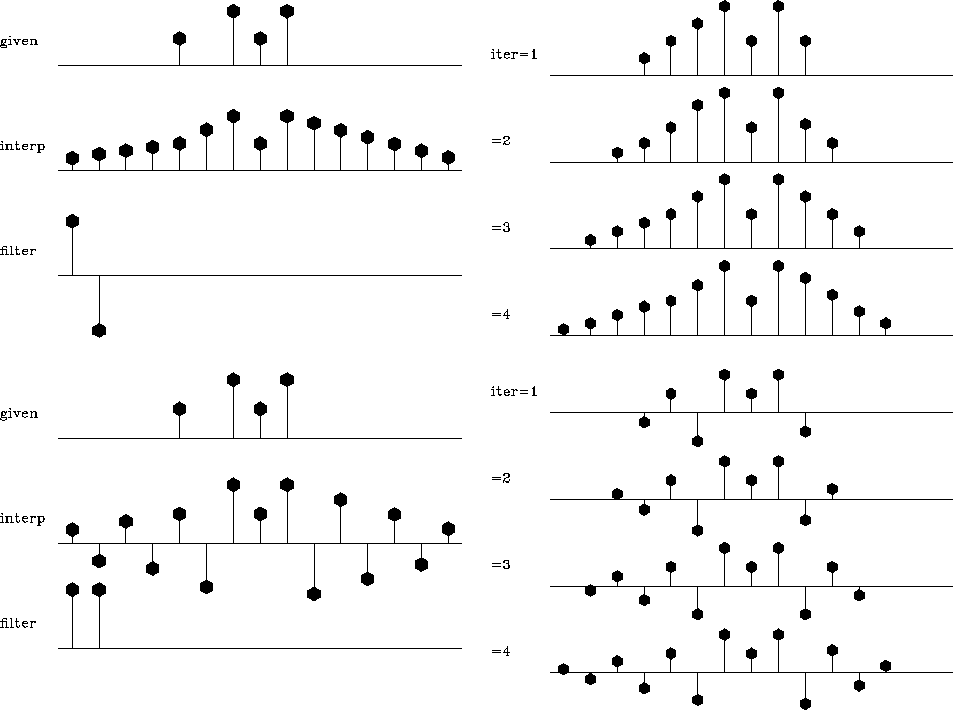
I illustrate the missing data problem with a simple 1-D synthetic data
test taken from Claerbout (1999). Figure shows the
interpolation results of the unpreconditioned technique with three
different filters. For comparison with the preconditioned scheme, I
changed the boundary convolution conditions from internal to truncated
transient convolution. As in the previous example, the system was
solved with a conjugate-gradient iterative optimization.
mall
Figure 8 Unpreconditioned
interpolation with two different regularization filters. Left plot:
the top shows the input data; the middle, the result of
interpolation; the bottom, the filter. The right plot shows the
convergence process for the first four iterations.





As depicted on the right side of the figures, the interpolation
process starts with a ``complicated'' model and slowly ``simplifies''
it until the final result is achieved.
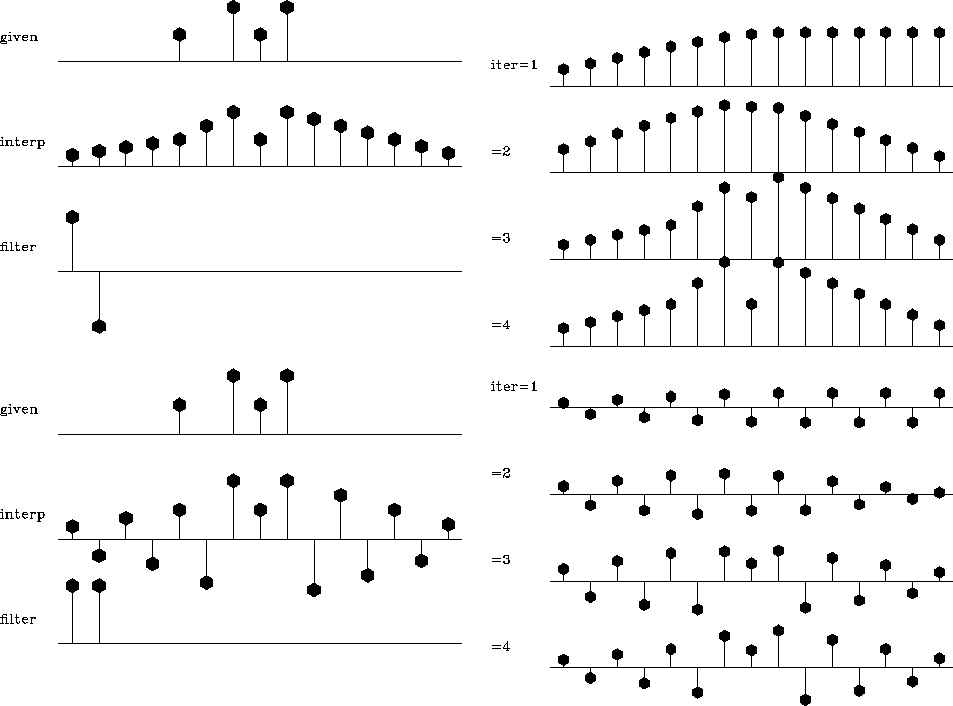
Preconditioned interpolation (Figure ) behaves
differently. At the early iterations, the model is simple. As the
iteration proceeds, new details are added into the model. After a
surprisingly small number of iterations, the output closely resembles
the final output. The final output of interpolation with recursive
deconvolution preconditioning is exactly the same as that of the
original method.
sall
Figure 9 Interpolation with
preconditioning. Left plot: the top shows the input data; the
middle, the result of interpolation; the bottom, the filter. The
right plot shows the convergence process for the first four
iterations.
The next section extends the idea of preconditioning by inverse
recursive filtering to multiple dimensions.
Next: Multidimensional recursive filter preconditioning
Up: One-dimensional synthetic examples
Previous: One-dimensional synthetic examples
Stanford Exploration Project
12/28/2000