




Next: Data regularization as an
Up: Fundamentals of data regularization
Previous: Statistical estimation
In order to understand the structure of the matrices 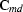 and
and 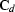 , we need to make some assumptions about the
relationship between the true model
, we need to make some assumptions about the
relationship between the true model 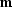 and the data
and the data
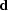 . A natural assumption is that if the model were known
exactly, the observed data would be related to it by a forward
interpolation operator
. A natural assumption is that if the model were known
exactly, the observed data would be related to it by a forward
interpolation operator 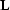 as follows:
as follows:
| 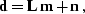 |
(4) |
where  is an additive observational noise. For simplicity,
we can assume that the noise is uncorrelated and normally distributed
around zero:
is an additive observational noise. For simplicity,
we can assume that the noise is uncorrelated and normally distributed
around zero:
| 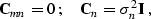 |
(5) |
where 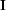 is an identity matrix of the data size, and
is an identity matrix of the data size, and
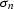 is a scalar. Assuming that there is no linear correlation
between the noise and the model, we arrive at the following
expressions for the second moment matrices in
formula (
is a scalar. Assuming that there is no linear correlation
between the noise and the model, we arrive at the following
expressions for the second moment matrices in
formula (![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) ):
):
| 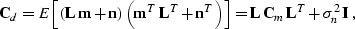 |
(6) |
| ![\begin{displaymath}
\bold{C}_{md} = E\left[\bold{m}\,
\left(\bold{m}^T\,\bold{L}^T + \bold{n}^T\right)\right] =
\bold{C}_{m}\,\bold{L}^T\;.\end{displaymath}](img29.gif) |
(7) |
Substituting equations () and () into
(), we finally obtain the following specialized form of
the Gauss-Markoff formula:
| 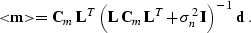 |
(8) |
Assuming that 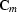 is invertible, we can also rewrite
equation () in a mathematically equivalent form
is invertible, we can also rewrite
equation () in a mathematically equivalent form
| 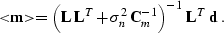 |
(9) |
The equivalence of formulas () and ()
follows from the simple matrix equality
| 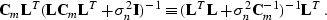 |
(10) |
It is important to note an important difference between
equations () and (): The inverted matrix
has data dimensions in the first case, and model dimensions in the
second case. I discuss the practical significance of this distinction
in Chapter .
In order to simplify the model estimation problem further, we can
introduce a local differential operator 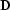 . A model complies with the operator if the residual after we apply
this operator
. A model complies with the operator if the residual after we apply
this operator 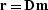 is uncorrelated and
normally distributed. This means that
is uncorrelated and
normally distributed. This means that
| ![\begin{displaymath}
E\left[\bold{D}\,\bold{m}\,\bold{m}^T\,\bold{D}^T\right] =
\bold{D}\,\bold{C}_m\,\bold{D}^T = \sigma_m^2\,\bold{I}\;,\end{displaymath}](img36.gif) |
(11) |
where the identity matrix has the model size. Furthermore,
assuming that is invertible, we can represent as follows:
| 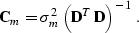 |
(12) |
Substituting formula () into () and
(), we can finally represent the model estimate in the
following equivalent forms:
| 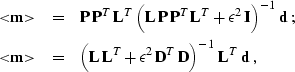 |
(13) |
| (14) |
where 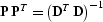 and
and 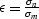 .
.
The first simplification step has now been accomplished. By
introducing additional assumptions, we have approximated the
covariance matrices and with the forward
interpolation operator and the differential operator
. Both and act locally on the model.
Therefore, they are sparse, efficiently computed operators. Different
examples of operators , , and 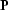 are
discussed later in this dissertation. In the next section, I proceed
to the second simplification step.
are
discussed later in this dissertation. In the next section, I proceed
to the second simplification step.
Next: Data regularization as an
Up: Fundamentals of data regularization
Previous: Statistical estimation
Stanford Exploration Project
12/28/2000