|
|
|
|
Linearised inversion with GPUs |
Chris Leader and Robert Clapp
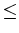 6 Gbytes, restricting model sizes that can be allocated). As shown in an earlier discussion the IO bottleneck on the adjoint side can be somewhat circumvented by using random domain boundaries. Herein will be discussed how the forward modelling routine must be adapted to create an adjoint pair such that least-squares iterative inversion can be performed. We will then analyse how domain decomposition and P2P communication can be used to propagate over larger model sizes in such a way that communication can be effectively hidden and subsequently we can observe linear scaling.
6 Gbytes, restricting model sizes that can be allocated). As shown in an earlier discussion the IO bottleneck on the adjoint side can be somewhat circumvented by using random domain boundaries. Herein will be discussed how the forward modelling routine must be adapted to create an adjoint pair such that least-squares iterative inversion can be performed. We will then analyse how domain decomposition and P2P communication can be used to propagate over larger model sizes in such a way that communication can be effectively hidden and subsequently we can observe linear scaling.
|
|
|
|
Linearised inversion with GPUs |