|
|
|
|
Linearised inversion with GPUs |
For smaller-scale research institutions, which may not have access to high performance computing facilities, processing terabytes of seismic data can be a significant challenge if attainable at all. As discussed in Ohmer et al. (2005) and Foltinek et al. (2009), GPUs can greatly assist any operation that can be considered as Single Instruction Multiple Data (SIMD) by running thousands of independent threads concurrently across the domain; two-way wave propagation can be considered as a SIMD operation as we are convolving a set stencil many times. However such a set up has disadvantages; the GPU can not read directly from disk, thus any disk based IO must be explicitly routed through a host CPU, compounding any such memory access. Furthermore the dynamic memory available on a GPU is 6 Gbytes or less, meaning that for propagation we are limited to a model size of 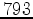 pt
pt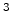 for modelling and
for modelling and 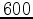 pts
for imaging, assuming we are using acoustic, isotropic propagators. These numbers are significantly reduced when performing anisotropic and/or elastic propagation. Clapp (2009) and Leader and Clapp (2011) discuss how Reverse Time Migration (RTM) can be adapted to minimise disk access during propagation and hence better harness the computational power of the GPU without sacrificing significant performance for data movement. This paper will look at extending this system to inversion and also at how larger model sizes can be used. From here on a basic familiarity of GPU memory hierarchies and their uses will be assumed, one can to refer to Micikevicius (2009) or Leader and Clapp (2011) for more in depth discussions of these attributes.
pts
for imaging, assuming we are using acoustic, isotropic propagators. These numbers are significantly reduced when performing anisotropic and/or elastic propagation. Clapp (2009) and Leader and Clapp (2011) discuss how Reverse Time Migration (RTM) can be adapted to minimise disk access during propagation and hence better harness the computational power of the GPU without sacrificing significant performance for data movement. This paper will look at extending this system to inversion and also at how larger model sizes can be used. From here on a basic familiarity of GPU memory hierarchies and their uses will be assumed, one can to refer to Micikevicius (2009) or Leader and Clapp (2011) for more in depth discussions of these attributes.
|
|
|
|
Linearised inversion with GPUs |