




Next: Routine for one step
Up: KRYLOV SUBSPACE ITERATIVE METHODS
Previous: Why steepest descent is
In the conjugate-direction method, not a line, but rather a plane,
is searched.
A plane is made from an arbitrary linear combination of two vectors.
One vector will be chosen to be the gradient vector, say 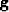 .The other vector will be chosen to be the previous descent step vector,
say
.The other vector will be chosen to be the previous descent step vector,
say 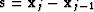 .Instead of
.Instead of 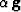 we need a linear combination,
say
we need a linear combination,
say 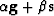 .For minimizing quadratic functions the plane search requires
only the solution of a two-by-two set of linear equations
for
.For minimizing quadratic functions the plane search requires
only the solution of a two-by-two set of linear equations
for  and
and 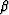 .The equations will be specified here along with the program.
(For nonquadratic functions a plane search is considered intractable,
whereas a line search proceeds by bisection.)
.The equations will be specified here along with the program.
(For nonquadratic functions a plane search is considered intractable,
whereas a line search proceeds by bisection.)
For use in linear problems,
the conjugate-direction method described in this book
follows an identical path with the more well-known conjugate-gradient method.
We use the conjugate-direction method
for convenience in exposition and programming.
The simple form of the conjugate-direction algorithm covered here
is a sequence of steps.
In each step the minimum is found in the plane given by two vectors:
the gradient vector and the vector of the previous step.
Given the linear operator 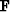 and a generator of solution steps
(random in the case of random directions or gradient in the case of
steepest descent),
we can construct an optimally convergent iteration process,
which finds the solution in no more than n steps,
where n is the size of the problem.
This result should not be surprising.
If is represented by a full matrix,
then the cost of direct inversion is proportional to n3,
and the cost of matrix multiplication is n2.
Each step of an iterative method boils down to a matrix multiplication.
Therefore, we need at least n steps to arrive at the exact solution.
Two circumstances make large-scale optimization practical.
First, for sparse convolution matrices
the cost of matrix multiplication is n instead of n2.
Second, we can often find a reasonably good solution
after a limited number of iterations.
If both these conditions are met, the cost of optimization
grows linearly with n,
which is a practical rate even for very large problems.
Fourier-transformed variables are often capitalized.
This convention will be helpful here,
so in this subsection only,
we capitalize vectors transformed by the matrix.
As everywhere, a matrix such as is printed in boldface type
but in this subsection,
vectors are not printed in boldface print.
Thus we define the solution, the solution step
(from one iteration to the next),
and the gradient by
and a generator of solution steps
(random in the case of random directions or gradient in the case of
steepest descent),
we can construct an optimally convergent iteration process,
which finds the solution in no more than n steps,
where n is the size of the problem.
This result should not be surprising.
If is represented by a full matrix,
then the cost of direct inversion is proportional to n3,
and the cost of matrix multiplication is n2.
Each step of an iterative method boils down to a matrix multiplication.
Therefore, we need at least n steps to arrive at the exact solution.
Two circumstances make large-scale optimization practical.
First, for sparse convolution matrices
the cost of matrix multiplication is n instead of n2.
Second, we can often find a reasonably good solution
after a limited number of iterations.
If both these conditions are met, the cost of optimization
grows linearly with n,
which is a practical rate even for very large problems.
Fourier-transformed variables are often capitalized.
This convention will be helpful here,
so in this subsection only,
we capitalize vectors transformed by the matrix.
As everywhere, a matrix such as is printed in boldface type
but in this subsection,
vectors are not printed in boldface print.
Thus we define the solution, the solution step
(from one iteration to the next),
and the gradient by
| 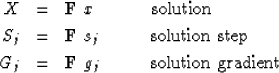 |
(55) |
| (56) |
| (57) |
A linear combination in solution space,
say s+g, corresponds to S+G in the conjugate space,
because 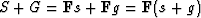 .According to equation
(40),
the residual is the theoretical data minus the observed data.
.According to equation
(40),
the residual is the theoretical data minus the observed data.
| 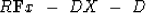 |
(58) |
The solution x is obtained by a succession of steps sj, say
| 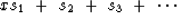 |
(59) |
The last stage of each iteration is to update the solution and the residual:
|  |
(60) |
| (61) |
The gradient vector g is a vector with the same number
of components as the solution vector x.
A vector with this number of components is
| 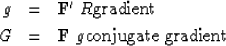 |
(62) |
| (63) |
The gradient g in the transformed space is G,
also known as the conjugate gradient.
The minimization (45) is now generalized
to scan not only the line with ,but simultaneously another line with .The combination of the two lines is a plane:
| 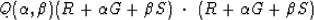 |
(64) |
The minimum is found at 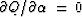 and
and
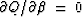 , namely,
, namely,
| 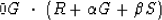 |
(65) |
| 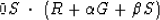 |
(66) |
The solution is
| ![\begin{displaymath}
\left[
\begin{array}
{c}
\alpha \\
\beta \end{array} \r...
...begin{array}
{c}
(G\cdot R) \\ (S\cdot R) \end{array} \right]\end{displaymath}](img160.gif) |
(67) |
This may look complicated.
The steepest descent method requires us to compute
only the two dot products
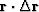 and
and
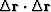 while equation (64) contains five dot products,
but the extra trouble is well worth while because the ``conjugate direction''
is such a much better direction than the gradient direction.
while equation (64) contains five dot products,
but the extra trouble is well worth while because the ``conjugate direction''
is such a much better direction than the gradient direction.
The many applications in this book all need to
find and with (67) and then
update the solution with (60) and
update the residual with (61).
Thus we package these activities in a subroutine
named cgstep().
To use that subroutine we will have a computation template
like we had for steepest descents, except that we
will have the repetitive work done by subroutine cgstep().
This template (or pseudocode) for minimizing the residual
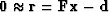 by the conjugate-direction method is
by the conjugate-direction method is
 iterate {
iterate {
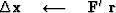
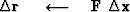
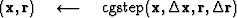 }
}
where
the subroutine cgstep()
remembers the previous iteration and
works out the step size and adds in
the proper proportion of the 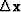 of
the previous step.
of
the previous step.
Next: Routine for one step
Up: KRYLOV SUBSPACE ITERATIVE METHODS
Previous: Why steepest descent is
Stanford Exploration Project
4/27/2004