Next: Real-time generation of multiple
Up: Path View: visualization of
Previous: Interpolating a path from
After path 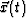 is calculated from the sample points, proper data processing is still required to clearly display the path. The path has only has length but no volume, making it nearly invisible. Thus, the path must attain some volume. A straightforward approach is to define a spherical neighborhood around the path. For each point , let the neighborhood be
is calculated from the sample points, proper data processing is still required to clearly display the path. The path has only has length but no volume, making it nearly invisible. Thus, the path must attain some volume. A straightforward approach is to define a spherical neighborhood around the path. For each point , let the neighborhood be
| 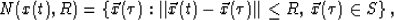 |
(6) |
where S is the data space and R is a variable radius of our selection. Our reason for making R variable is explained near the end of this section. The existence of the neighborhood greatly improves the visibility of the path when the path is buried in the interior of a data volume. Now, instead of a fine string, a bloated tube exists.
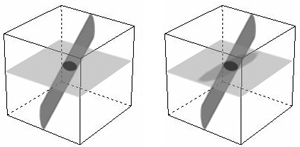
Ordinary projection techniques still present problems of visibility. Consider the case depicted on the left of Fig. 7. If a plane slices the path in the middle as shown, only an oval will appear on that plane. The rest of the path can only be revealed as we move the plane up and down but each time still is limited to just an oval. Instead, we want to see a longer portion of the path projected onto the plane, depicted on the right side of Fig. 7. The region of intersection should be most clearly visible, but the other regions should cast shadows onto the plane. Moreover, this effect should occur in all three viewing dimensions.
chen-cube-model
Figure 7 Projection without shadowing (left) and with shadowing (right).

A novel projection algorithm is developed to improve path visibility. Three new volumes 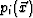 ,
, 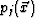 , and
, and 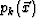 equal in size to the original volume
equal in size to the original volume 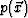 are created, corresponding to the three viewing directions
are created, corresponding to the three viewing directions 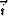 ,
, 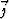 , and
, and 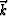 . We now show the algorithm for projection along , which produces a set of - slices, but the method is applied analogously along or . The steps of the algorithm are:
. We now show the algorithm for projection along , which produces a set of - slices, but the method is applied analogously along or . The steps of the algorithm are:
- 1.
- Volume
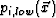 is filled with a dimmed version of , specifically
is filled with a dimmed version of , specifically 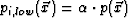 , where we have used
, where we have used 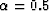 . This serves as a background for the paths.
. This serves as a background for the paths.
- 2.
- Every path point's influence needs to be extended beyond the point's immediate location. A useful metric is the orthogonal distance between a point P and a plane D, which is defined as the distance between P and the point in D closest to P. For a - slice located along at xs,i and a path point
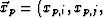
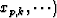 , the closest point on the slice to
, the closest point on the slice to 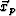 is
is 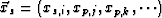 . Thus, the orthogonal distance is |xp,i - xs,i|. If this distance is small enough, then a scaled version of the data value at in should be shown at
. Thus, the orthogonal distance is |xp,i - xs,i|. If this distance is small enough, then a scaled version of the data value at in should be shown at 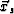 in . Specifically, for all on the path,
in . Specifically, for all on the path,
| 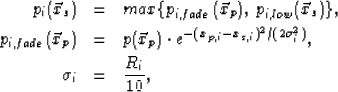 |
(7) |
| (8) |
| |
where Ri is the range of the data volume along direction . The value 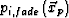 defined by Eq. 8 is the data value on the path from the original volume attenuated by a Gaussian fading factor. The fading factor decreases as the path point and the - slice are separated farther. Eq. 7 sets a lower threshold for using the attenuated values.
defined by Eq. 8 is the data value on the path from the original volume attenuated by a Gaussian fading factor. The fading factor decreases as the path point and the - slice are separated farther. Eq. 7 sets a lower threshold for using the attenuated values.
- 3.
- The previous step only covers projection at points on the path and should be repeated for every point
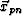 in the path neighborhood
in the path neighborhood 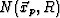 defined by Eq. 6. Redefine to be the closest point on the - slice to :
defined by Eq. 6. Redefine to be the closest point on the - slice to : 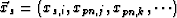 . For all xp on the path and for all
. For all xp on the path and for all 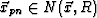 ,
,
| 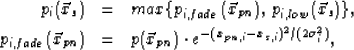 |
(9) |
| (10) |
The variable radius R plays an interesting role here. There is one problem inherent in projection: loss of distance information along the direction of projection. Far and near portions of the path should be displayed differently on a plane of projection. The Gaussian fading in Eq. 10 helps in this regard, but a stronger indicator is needed. Towards this end, R is made to be a monotonically increasing function of the distance between the point and , the point on the - slice closest to .
| 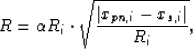 |
(11) |
where 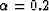 and Ri is again the range along direction . Since
and Ri is again the range along direction . Since 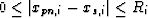 , the square root term is between 0 and 1 and increases as and are farther away. Therefore, on any plane of projection, distant parts of a path will appear dimmer due to Eq. 10 and thicker due to Eq. 11, while near parts of a path will appear undimmed and thinner. Recovery of distance information along the direction of projection is achieved.
, the square root term is between 0 and 1 and increases as and are farther away. Therefore, on any plane of projection, distant parts of a path will appear dimmer due to Eq. 10 and thicker due to Eq. 11, while near parts of a path will appear undimmed and thinner. Recovery of distance information along the direction of projection is achieved.
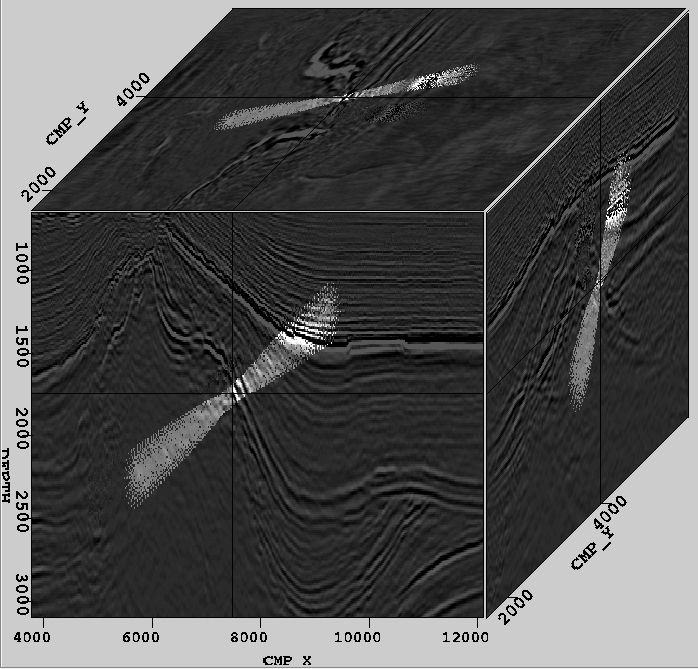
Fig. 8 shows projections onto slices in all three viewing dimensions for a path traversing a volume diagonally. As the projection radius grows and the projection intensity fades, the underlying path being projected is farther away from the current slice.
chen-pathview
Figure 8 Projection of a diagonal path onto orthogonal planes.
Next: Real-time generation of multiple
Up: Path View: visualization of
Previous: Interpolating a path from
Stanford Exploration Project
1/16/2007