




Next: Looking at data-space
Up: Background
Previous: Background
As described in Lomask (1998), we use inversion to find the model (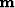 ) that when sampled into data-space using linear interpolation (
) that when sampled into data-space using linear interpolation (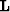 ) will have a derivative (
) will have a derivative (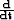 ) that will equal the derivative of the data (
) that will equal the derivative of the data (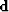 ).
). 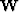 is a weighting operator that merely throws out fitting equations that are contaminated with noise or track ends.
Expressed as a fitting goal, this is :
is a weighting operator that merely throws out fitting equations that are contaminated with noise or track ends.
Expressed as a fitting goal, this is :
| ![\begin{eqnarray}
\ {\bf W} \frac{d}{dt}[{\bf L}{\bf m} -{\bf d}] &\approx& {\bf 0}.
\
\end{eqnarray}](img6.gif) |
(1) |
For the sparse tracks or missing bins, we add a regularization fitting goal to properly fill in the data. Our fitting goals are now:
| ![\begin{eqnarray}
\ {\bf W} \frac{d}{dt}[{\bf L}{\bf m} -{\bf d}] &\approx& {\bf 0} \nonumber \\ \ \epsilon {\bf A m} &\approx& {\bf 0} .
\end{eqnarray}](img7.gif) |
|
| (2) |
Applying these goals on the dense data, we get the smooth result in Figure 3.
fulldenseNoRuf
Figure 3 Result of applying fitting goals (equation 2).





To make it look more interesting, we roughen the model by taking the first derivative in the east-west direction as in Figure 4. This highlights alot of the minor north-south oriented ridges. Similarly, we can roughen it in the north-south direction as in Figure 5. This highlights the central main ridge. Applying the helical derivative, we get the results in Figure 6. Unlike the directional derivative operators, this highlights features with less directional bias. Lastly, we take the east-west second derivative to get the very crisp image in Figure 7.
fulldense1
Figure 4 Results of fitting goals with east-west derivative.
fulldenseNS1
Figure 5 Results of fitting goals with north-south derivative.
helix
Figure 6 Results of fitting goals with helix derivative.
fulldense2nd1
Figure 7 Results of fitting goals with east-west 2nd derivitive.
Next: Looking at data-space
Up: Background
Previous: Background
Stanford Exploration Project
6/8/2002




