




iterate {

![$\bold W \quad\longleftarrow\quad{\bf diag}[w(\bold r)]$](img54.gif)
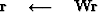
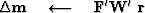

 }
}
where
Now let us see how the weighting functions relate
to robust estimation:
Notice in the code template that ![]() is applied twice
in the definition of
is applied twice
in the definition of ![]() .Thus
.Thus ![]() is the square root of the diagonal operator
in equation (13).
is the square root of the diagonal operator
in equation (13).
 |
(14) |
Module solver_irls ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) implements the computational template above. In addition to the usual
set of arguments from the solver() subroutine
, it accepts a user-defined function (parameter
wght) for computing residual weights. Parameters
nmem and nfreq control the restarting schedule of
the iterative scheme.
solver_irlsiteratively reweighted optimization
implements the computational template above. In addition to the usual
set of arguments from the solver() subroutine
, it accepts a user-defined function (parameter
wght) for computing residual weights. Parameters
nmem and nfreq control the restarting schedule of
the iterative scheme.
solver_irlsiteratively reweighted optimization
We can ask whether cgstep(), which was not designed
with nonlinear least-squares in mind, is doing the right thing
with the weighting function.
First, we know we are doing weighted linear least-squares correctly.
Then we recall that on the first iteration, the conjugate-directions
technique reduces to steepest descent,
which amounts to a calculation of
the scale factor ![]() with
with
| |
(15) |
Experience shows that difficulties arise when the weighting function varies rapidly from one iteration to the next. Naturally, the conjugate-direction method, which remembers the previous iteration, will have an inappropriate memory if the weighting function changes too rapidly. A practical approach is to be sure the changes in the weighting function are slowly variable.