




Next: Short memory of the
Up: WHAT ARE ADJOINTS FOR?
Previous: WHAT ARE ADJOINTS FOR?
The orthogonality principle (25) transforms according to the
dot-product test (27) to the form
| 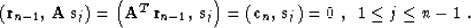 |
(29) |
Forming the dot product 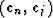 and
applying formula (22), we can see that
and
applying formula (22), we can see that
| 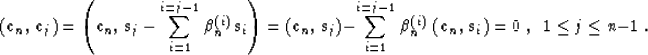 |
(30) |
Equation (30) proves the orthogonality of the gradient directions from
different iterations. Since the gradients are orthogonal, after n
iterations they form a basis in the n-dimensional space. In other
words, if the model space has n dimensions, each vector in this
space can be represented by a linear combination of the gradient
vectors formed by n iterations of the conjugate-gradient
method. This is true as well for the vector 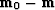 , which
points from the solution of equation (1) to the initial
model estimate
, which
points from the solution of equation (1) to the initial
model estimate 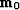 . Neglecting computational errors, it takes
exactly n iterations to find this vector by successive optimization
of the coefficients. This proves that the
conjugate-gradient method converges to the exact solution in a
finite number of steps (assuming that the model belongs to a
finite-dimensional space).
. Neglecting computational errors, it takes
exactly n iterations to find this vector by successive optimization
of the coefficients. This proves that the
conjugate-gradient method converges to the exact solution in a
finite number of steps (assuming that the model belongs to a
finite-dimensional space).
The method of conjugate gradients simplifies formula (26)
to the form
| 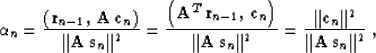 |
(31) |
which in turn leads to the simplification of formula (8),
as follows:
| 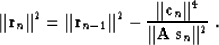 |
(32) |
If the gradient is not equal to zero, the residual is guaranteed to
decrease. If the gradient is equal to zero, we have already
found the solution.
Next: Short memory of the
Up: WHAT ARE ADJOINTS FOR?
Previous: WHAT ARE ADJOINTS FOR?
Stanford Exploration Project
11/12/1997