




Next: Editing in two-dimensional data
Up: Algorithm
Previous: Algorithm
As an example of editing one-dimensional data,
consider a time series such as the following:
| 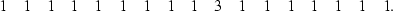 |
(5) |
It is obvious that one sample does not follow the pattern of the
majority of the samples.
A prediction may be made on these samples by applying the filter
| 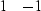 |
(6) |
to the data,
giving a result of
| 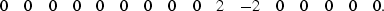 |
(7) |
While the exception is more visible,
the residual is now spread over two samples.
Applying the same filter in the reverse direction produces
| 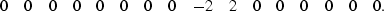 |
(8) |
Much the same residual has been obtained as in (![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) ),
but it has now been smeared in the other direction.
To find the sample that has caused the residual,
the maximum of the absolute values of corresponding
samples from both filtered series
can be taken.
For the filtered series in () and (),
the result is
),
but it has now been smeared in the other direction.
To find the sample that has caused the residual,
the maximum of the absolute values of corresponding
samples from both filtered series
can be taken.
For the filtered series in () and (),
the result is
|  |
(9) |
The troublesome sample is now easy to distinguish.
To detect it automatically,
a quantitative criteria for the expected size of the residuals must be used.
A number of criteria are available,
including some multiple of the average, the median, or the RMS.
For the cases likely to appear in seismic data,
a multiple of the median of the residuals
is likely to produce the most robust measure.
This measure will be used as the threshold value indicating a noisy sample
in the discussions that follow.
Next: Editing in two-dimensional data
Up: Algorithm
Previous: Algorithm
Stanford Exploration Project
2/9/2001