




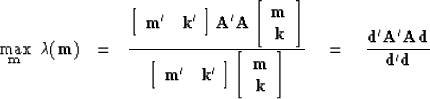 |
(1) |
In the physical problem,
the components of ![]() and
and ![]() randomly interleave one another
and there are huge numbers of components of each.
To gain some insight and see how classical mathematics is relevant,
forget for a moment the distinction between known and missing data
and imagine that all the components of the data field
randomly interleave one another
and there are huge numbers of components of each.
To gain some insight and see how classical mathematics is relevant,
forget for a moment the distinction between known and missing data
and imagine that all the components of the data field ![]() are independent variables.
Then, it is well known (and I will repeat the proof below)
that the stationary values of
are independent variables.
Then, it is well known (and I will repeat the proof below)
that the stationary values of ![]() in
(1)
are the family of eigenvalues.
So if components of
in
(1)
are the family of eigenvalues.
So if components of ![]() happen to be components of the
eigenvector of maximum eigenvalue,
then maximization of
happen to be components of the
eigenvector of maximum eigenvalue,
then maximization of ![]() will bring
will bring ![]() to the remaining components of that
eigenvector of maximum eigenvalue.
My conjecture is that in practice we would find
that maximization of
to the remaining components of that
eigenvector of maximum eigenvalue.
My conjecture is that in practice we would find
that maximization of ![]() would lead to estimated missing data
would lead to estimated missing data ![]() that best fits the various components in the known data
that best fits the various components in the known data ![]() .
.
In many of our applications, ![]() is roughly a unitary matrix
because it arises from wave propagation problems.
Think of
is roughly a unitary matrix
because it arises from wave propagation problems.
Think of ![]() this way: The denominator limits the total energy;
In such cases, maximization should quickly exclude evanescent energy,
but a huge number of eigenvalues are all the same,
so the maximization is extremely nonunique.
To obtain uniqueness with unitary operators
we need to introduce a weighting function such as
this way: The denominator limits the total energy;
In such cases, maximization should quickly exclude evanescent energy,
but a huge number of eigenvalues are all the same,
so the maximization is extremely nonunique.
To obtain uniqueness with unitary operators
we need to introduce a weighting function such as
![]() .
.
The mathematical problem with the ![]() constraints however,
was unknown to Michael Saunders.
Since it is a nonlinear problem
we should be wary of multiple unwanted solutions,
but that need not stop us from trying.
My proposed method for the optimization
(1)
follows from what I know
about conjugate gradients: First we easily find a gradient and
keep a vector representing the previous step.
Second, scaling these by
constraints however,
was unknown to Michael Saunders.
Since it is a nonlinear problem
we should be wary of multiple unwanted solutions,
but that need not stop us from trying.
My proposed method for the optimization
(1)
follows from what I know
about conjugate gradients: First we easily find a gradient and
keep a vector representing the previous step.
Second, scaling these by ![]() and
and ![]() respectively,
respectively,
![]() is a simple ratio of quadratic forms in two variables.
After getting the coefficients of these quadratic forms
the problem is of such low dimensionality (two) that
almost any method should suffice.
is a simple ratio of quadratic forms in two variables.
After getting the coefficients of these quadratic forms
the problem is of such low dimensionality (two) that
almost any method should suffice.