|
|
|
|
Accelerating 3D convolution using streaming architectures on FPGAs |
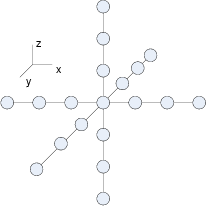
Our target application uses a a 7-point `star' stencil (Figure 2(a)) to perform the 8th order finite difference. In our exploration, beside the `star' stencil, we also consider a 3-by-3-by-3 `cube' stencil (Figure 2(b)), which performs a 6th order finite difference (Spotz and Carey 1996).
|
|---|
|
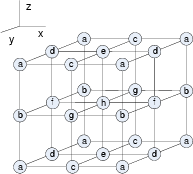
star,cube
Figure 2. Different 3D stencils: `star' vs. `cube'. |
|
|
In software implementations, the `cube' and the `star' stencils provide a similar performance. For the FPGA implementations, the resource costs for the `star' and the `cube' stencils are different. The upper part of Table 3 shows the straightforward implementations of `star' and `cube' stencils for a 120x120x120 array. The `cube' consumes 20% more DSP48E arithmetic units than `star', as it involves more multiplications. Meanwhile, the memory cost (BRAM) of the `cube' is one third of the `star', as the data buffering requirement decreases from 6 slices to 2 slices.
| Normal Stencils | `star' | `cube' | |
| FPGA | #slices | 5618 | 7072 |
| resource | #BRAMs | 87 | 30 |
| costs | #DSP48Es | 50 | 60 |
| Optimized Stencils | `star' | `cube' | |
| FPGA | #slices | 5207 | 6256 |
| resource | #BRAMs | 87 | 30 |
| cost | #DSP48Es | 32 | 18 |
For the FPGA designs, we can reduce the count of arithmetic operations by exploiting the symmetry of the coefficients. For example, in the `cube' stencil shown in Figure 2(b), the stencil coefficients are the same for the points marked with the same letters, as both the Laplace derivatives and the scaling ratio determined by the sampling rate of different axes are the same for these points. Therefore, instead of computing
![]() , we compute
, we compute
![]() . Applying this technique, the computation for the `cube' stencil reduces from 27 multiplications and 26 additions to 8 multiplications and 26 additions, while the `star' stencil reduces from 19 multiplications and 18 additions to 10 multiplications and 18 additions. The lower part of Table 3 shows the resource costs for multiplication-reduced `cube' and `star'. While the cost of BRAMs remains the same, the number of DSP48Es reduces significantly for the `cube'. After the multiplication reduction, the `cube' consumes much less than the `star' for both DSP48Es and BRAMs. The `star' consumes less logic slices as it involves fewer additions.
. Applying this technique, the computation for the `cube' stencil reduces from 27 multiplications and 26 additions to 8 multiplications and 26 additions, while the `star' stencil reduces from 19 multiplications and 18 additions to 10 multiplications and 18 additions. The lower part of Table 3 shows the resource costs for multiplication-reduced `cube' and `star'. While the cost of BRAMs remains the same, the number of DSP48Es reduces significantly for the `cube'. After the multiplication reduction, the `cube' consumes much less than the `star' for both DSP48Es and BRAMs. The `star' consumes less logic slices as it involves fewer additions.
As the stencil operator only consumes 8 or 10 multiplications and 26 or 18 additions, the FPGA has the capacity for multiple copies of the stencil operators. Therefore, we have two different ways to improve the performance of the FPGA: (1) using multiple stencil operators to work on multiple data items in parallel; (2) processing multiple time steps in one pass. The following sections discusses these two options in more detail.
|
|
|
|
Accelerating 3D convolution using streaming architectures on FPGAs |