|
|
|
|
Accelerating 3D convolution using streaming architectures on FPGAs |
To make a full utilization of all the units on an FPGA, we can try to fit as many stencil operators as possible into the chip. For the example shown in Figure 1, instead of processing only (3,3), we can process consecutive data items (such as (3,2), (3,3), and (3,4)) in parallel.
However, increasing the number of stencil units does not always improve the overall performance due to the constraint of the bandwidth between the FPGA and the onboard memories, which is approximately 13 GB/s in our platform. Considering the controlling overheads, the bandwidth for pure input and output data is around 8 GB/s. When the input streams for the multiple stencil operators approach the saturation point of the memory bandwidth, increasing the number of stencil operators may not improve the performance any more.
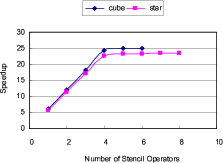
Using measured experiment results, we built a software tool that models the costs and performance of various FPGA designs. Figure 3 shows the estimated performance for processing a
![]() 3D convolution using different number of computation cores on an FPGA. The FPGA circuit is running at 125 MHz. The speedup is calculated against a single-core software implementation running on Intel Xeon 2.0 GHz. Due to the constraint of logic slices, the FPGA can fit six concurrent `cube' stencils or eight concurrent `star' stencils. For all the different number of stencil operators, the `cube' provides a slightly better performance than the `star'. Both the `cube' and the `star' arrive at the saturation point of around 25x speedup with four stencil operators.
3D convolution using different number of computation cores on an FPGA. The FPGA circuit is running at 125 MHz. The speedup is calculated against a single-core software implementation running on Intel Xeon 2.0 GHz. Due to the constraint of logic slices, the FPGA can fit six concurrent `cube' stencils or eight concurrent `star' stencils. For all the different number of stencil operators, the `cube' provides a slightly better performance than the `star'. Both the `cube' and the `star' arrive at the saturation point of around 25x speedup with four stencil operators.
|
multiple-cores
Figure 3. Speedups for processing a |
|
|---|---|
|
|
|
|
|
|
Accelerating 3D convolution using streaming architectures on FPGAs |