|
|
|
|
Many-core and PSPI: Mixing fine-grain and coarse-grain parallelism |
|
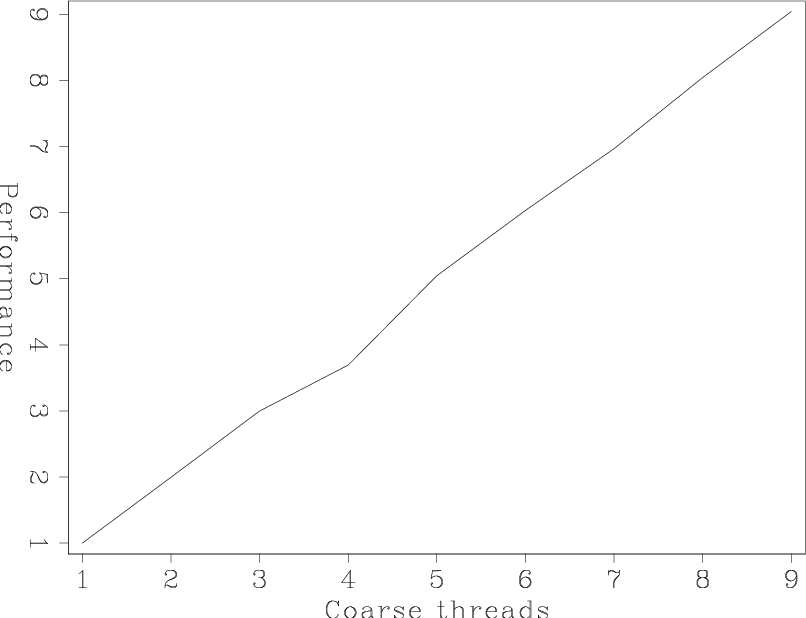
coarse
Figure 2. Performance as a function of the number of coarse-grained threads. [NR] |
|
|---|---|
|
|
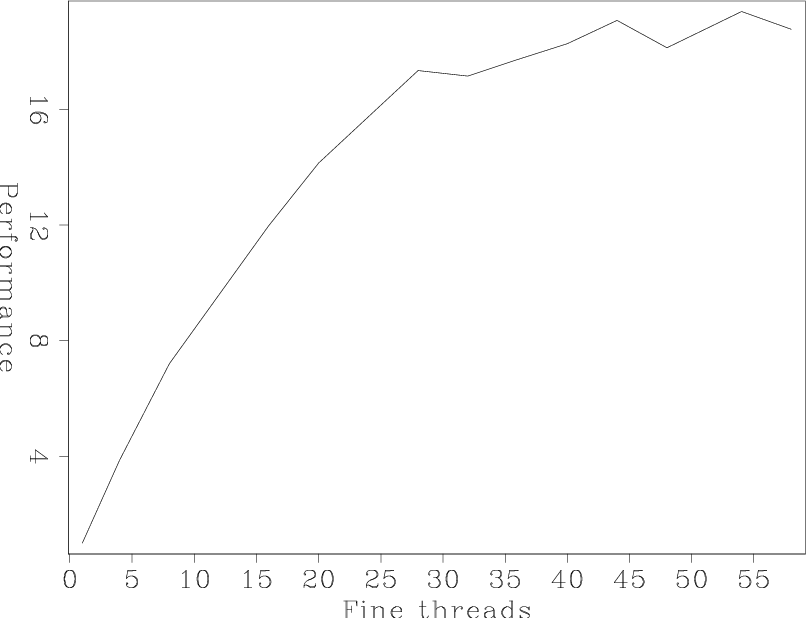
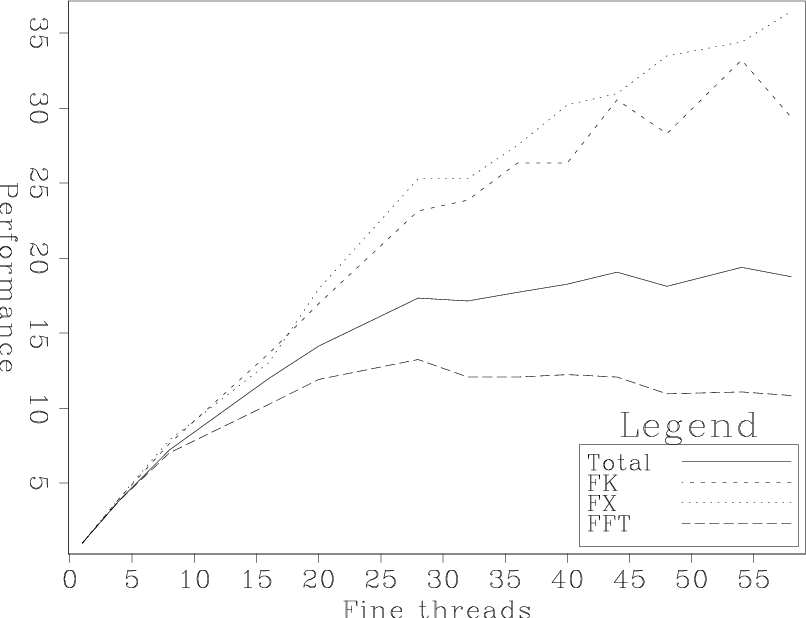
We then parallelized the FX, FK, and FFT routines. The FK and FX routines are sample by sample operations well suited to fine-grain parallelism and generally trivial to parallelize using the pthreads library. For the FFT, we used Sun's prime factor FFT rather than FFTW. The single-thread performance of the Sun's library was nearly double FFTW's performance. Figure 3 shows the normalized performance as the number of fine-grain threads increase. Note how we achieve nearly no performance gain after 32 threads. Figure 4 explains the lack of improvement. It shows the performance of the FFTW, FK, and FX steps portion of the algorithm. After 20-25 threads the FFT shows no performance improvements. This is not surprising due to the synchronization inherent in the FFT algorithm.
|
fine
Figure 3. Normalized performance as a function of the number of fine-grained threads. Note that little performance gain is achieved after 32 fine-grain threads. [NR] |
|
|---|---|
|
|
|
part
Figure 4. Performance as a function of the number of fine-grained threads for different parts of the algorithms. Not the nearly linear speed up of the FK and FX steps while performance peaks for the FFT at 20 threads. [NR] |
|
|---|---|
|
|
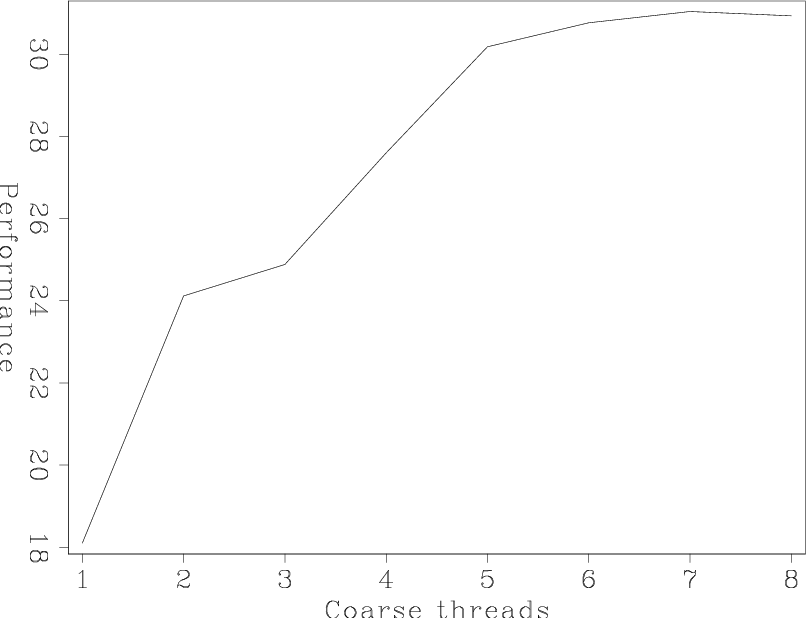
As a final test we combined the coarse-grained and fine-grained approaches. Figure 5
shows the maximum performance as a function of coarse-grain threads ![]() . For each coarse-grain
thread we used
. For each coarse-grain
thread we used ![]() fine-grain threads where
fine-grain threads where
![]() , maximizing the available
threads on the machine. Note that the graph is normalized by the single thread performance.
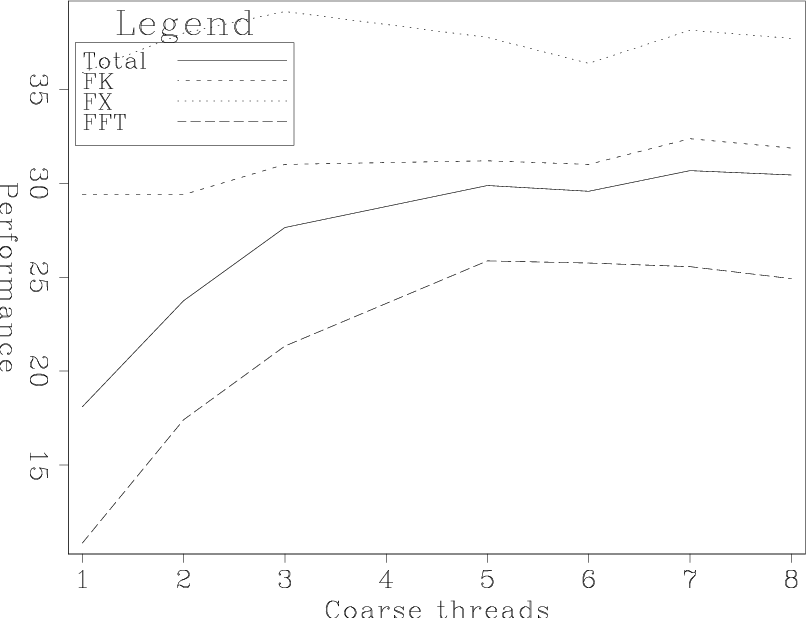
Peak performance was achieved using 6 or more coarse-grain threads. Figure 6
shows the break down by function. Not surprisingly, the FK and FX step show nearly constant
performance independent of the number coarse-grain vs. fine-grain threads. On the other
hand the FFT benefits from less fine-grained parallelism bringing up the overall total performance
of the algorithm.
, maximizing the available
threads on the machine. Note that the graph is normalized by the single thread performance.
Peak performance was achieved using 6 or more coarse-grain threads. Figure 6
shows the break down by function. Not surprisingly, the FK and FX step show nearly constant
performance independent of the number coarse-grain vs. fine-grain threads. On the other
hand the FFT benefits from less fine-grained parallelism bringing up the overall total performance
of the algorithm.
|
best
Figure 5. Performance as a function of number of coarse-grain threads. The number of fine-grain |
|
|---|---|
|
|
|
partb
Figure 6. Performance of different routines with the PSPI algorithm as a function of the number of coarse-grain threads. Note how the FFT benefits the most from more coarse-grain parallelism. [NR] |
|
|---|---|
|
|
As a comparison we run the same code on 4-core 1.8GHz, dual processor intel machine. Running 8 coarse-grain threads and normalizing in terms of the the Niagara2 single thread results we found:
| Segment | Relative speed |
| FFT | 23.9 |
| FX | 10.9 |
| FK | 61.8 |
| Total | 23.9 |
Improving the floating point and vector potential of the Niagara architecture could have a large impact on these results. Both the FFT and the FK steps involve significant floating point computations. The synchronization requirements of the FFT algorithm limits effective scaling to approximately 16 threads even for large volumes.
|
|
|
|
Many-core and PSPI: Mixing fine-grain and coarse-grain parallelism |