 |
 |
 |
 | Many-core and PSPI: Mixing fine-grain and coarse-grain parallelism |  |
![[pdf]](icons/pdf.png) |
Next: Results
Up: Liaw and Clapp: Niagara2
Previous: Niagara2 Overview
Downward
continued migration comes in various flavors including Common Azimuth Migration
(Biondi and Palacharla, 1996),
shot profile migration, source-receiver migration, plane-wave or delayed
shot migration, and narrow azimuth migrations.
For downward continued based migration there are four potential computational
bottlenecks that vary depending on the flavor of the downward continuation
algorithm. The Phase-Shift Plus Interpolation (PSPI) method is one of
the easier methods to implement. The computational cost is dominated
by the cost of downward propagating a wavefield at a given frequency  ,
a given depth step
,
a given depth step 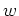 . Within this loop the wavefield is Fourier transformed,
a correction term in the FX domain is applied, and the wavefield is downward
continued in the FK domain. Pseudo code for the algorithm takes the following form,
. Within this loop the wavefield is Fourier transformed,
a correction term in the FX domain is applied, and the wavefield is downward
continued in the FK domain. Pseudo code for the algorithm takes the following form,
Loop over w{ !CORASE
Loop over z{
Loop over source/receiver{
Loop over v{
FX !FINE
IFFT !FINE
FK !FINE
}
FFT !FINE
}
}
}
In many cases the dominant cost is the FFT step. The dimensionality
of the FFT varies from 1-D (tilted plane-wave migration (Shan and Biondi, 2007))
to 4-D (narrow azimuth migration (Biondi, 2003)).
The FFT cost is often dominant due its 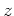 cost ratio,
cost ratio, 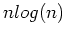 being the number of points in the transform, and the
non-cache friendly nature of multi-dimensional FFTs. The FK step,
which involves evaluating a square root function and performing
complex exponential is a second potential bottleneck. The high operational count
per sample can eat up significant cycles. The FX step, which involves a complex
exponential, or sine/cosine multiplication, has a similar, but computationally
less demanding, profile.
being the number of points in the transform, and the
non-cache friendly nature of multi-dimensional FFTs. The FK step,
which involves evaluating a square root function and performing
complex exponential is a second potential bottleneck. The high operational count
per sample can eat up significant cycles. The FX step, which involves a complex
exponential, or sine/cosine multiplication, has a similar, but computationally
less demanding, profile.
|
|
|
|
| Many-core and PSPI: Mixing fine-grain and coarse-grain parallelism | |
|
Next: Results
Up: Liaw and Clapp: Niagara2
Previous: Niagara2 Overview
2009-04-13