




![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) can be seen as an outlier
that attracts much of the solver's efforts during the filter estimation.
can be seen as an outlier
that attracts much of the solver's efforts during the filter estimation.
|
filterl2
Figure 3 Shaping filter estimated for the 1-D problem with the | 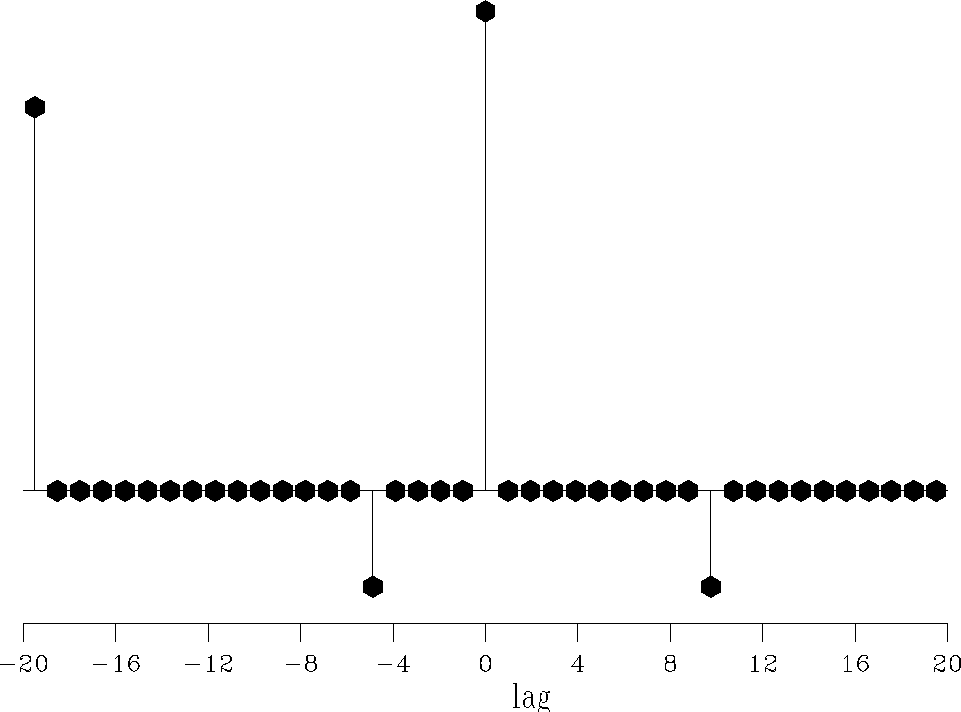 |





|
filterl1
Figure 4 Shaping filter estimated for the 1-D problem with the | 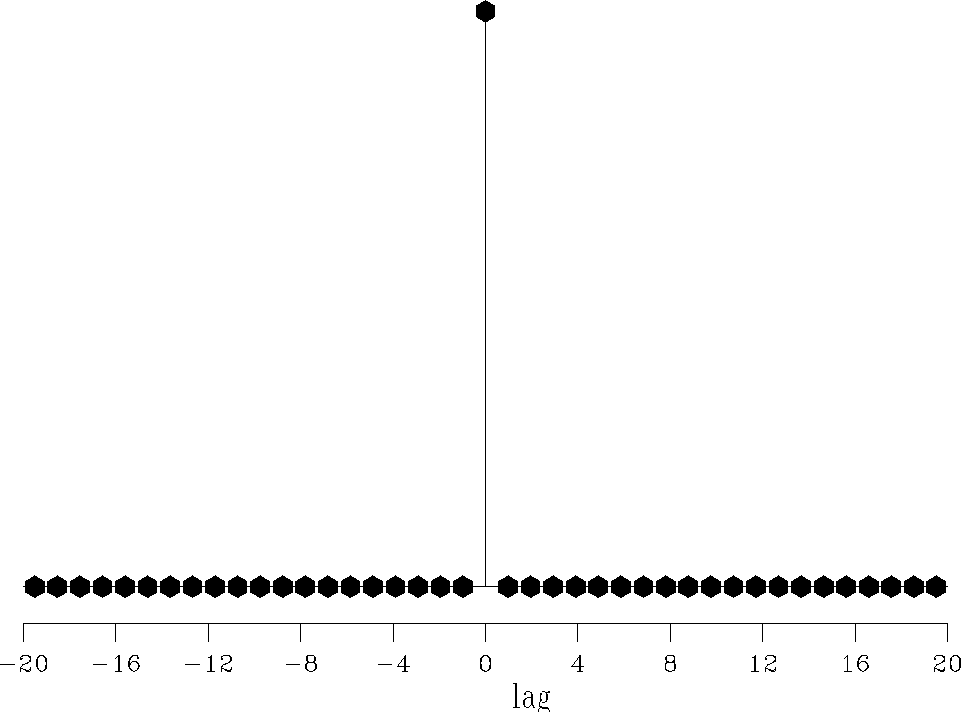 |
Consequently, some of the signal leaks into the
noise. Because the ![]() norm is robust to outliers, I propose
estimating the filter coefficients with it. This insensitivity to large
``noise'' has a statistical interpretation: robust measures are
related to long-tailed density functions in the same way that
norm is robust to outliers, I propose
estimating the filter coefficients with it. This insensitivity to large
``noise'' has a statistical interpretation: robust measures are
related to long-tailed density functions in the same way that ![]() is related to the short-tailed gaussian density function Tarantola (1987).
In this section, I show that the
is related to the short-tailed gaussian density function Tarantola (1987).
In this section, I show that the ![]() norm solves the problem
highlighted in the preceding section.
norm solves the problem
highlighted in the preceding section.
Now our goal is to estimate one shaping filter ![]() that minimizes
the objective function
that minimizes
the objective function
| |
(10) |
) is singular where any residual
component vanishes implying that the derivative of
Alternatively, the Huber norm is utilized.
This technique yields a good approximation of the ![]() norm.
Therefore, the objective function we minimize becomes
norm.
Therefore, the objective function we minimize becomes
| |
(11) |
). The only parameter that
needs to be set is ). Consistent with
the strategy of Chapter , I set
| (12) |