




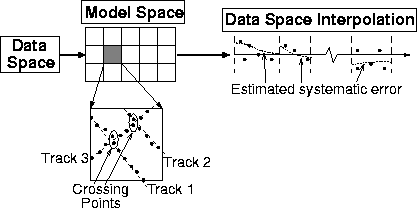
It is fairly easy to compute ``crossing points'' from the raw data. I partition the data spatially into fairly small regions and, using a Fortran90 data structure, store the track index of each data point in the region. I decide that two data points cross if they belong to different tracks and are separated (spatially) by a distance less than a predefined threshold.
Unraveling the distribution of errors between the two crossing points is a much more difficult, and possibly intractable problem, in the absence of prior information. In general, each of the two crossing points contain an unknown combination of systematic and random error. In this case, I simply ``split the difference'' by assuming that, given a measured difference between two crossing points, the systematic error is distributed evenly between the two points.
Once I have a series of measured differences at crossing points, I estimate the systematic error at all points in the data space by solving a least squares missing data problem. I impose the assumption that the systematic error is smooth along acquisition tracks by adding a roughness penalty to the least squares objective function. In least squares fitting goals, these ideas are written as follows.
| |
||
| (4) |
 |
