




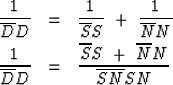 |
(1) | |
| (2) |
| |
(3) |
Now we are ready for the Spitz approximation.
Spitz builds his applications upon
the assumption that we can estimate D
and N from suitable chunks of raw data.
His result may be obtained from
(3) by ignoring its denominator getting
![]() or
or
| (4) |
Obviously the major difference between
![]() and
and ![]() is where the noise is large.
Thus it is for ``organized and predictable'' noises (small N)
where we expect to see the main difference.
is where the noise is large.
Thus it is for ``organized and predictable'' noises (small N)
where we expect to see the main difference.
Theoretically, we need not make the Spitz approximation. We could solve (1) for S by spectral factorization. Although the S obtained would be more theoretically satisfying, there would be some practical disadvantages. Getting the signal spectrum by subtracting that of the noise from that of the data leaves the danger of a negative result (which explodes the factorization). Thus, maintaining spectral positivity would require extra care. All these extra burdens are avoided by making the Spitz approximation. All the more so in applications with continuously varying estimates.