We are looking for the solution of the linear operator equation
(1)
where is the unknown model in the linear model space, stands for the given data, and is the forward modeling
operator. The data vector belongs to a Hilbert space with
a defined norm and dot product. The solution is constructed by iterative
steps in the model space, starting from an initial guess . Thus, at the n-th iteration, the current model is
found by the recursive relation
(2)
where denotes the step direction, and stands
for the scaling coefficient. The residual at the n-th iteration is
defined by
For a given step , we can choose to minimize the
squared norm of the residual
(5)
The parentheses denote the dot product, and
denotes the norm of x in the
corresponding Hilbert space. The optimal value of is easily
found from equation (5) to be
(6)
Two important conclusions immediately follow from this fact. First,
substituting the value of from formula (6) into
equation (4) and multiplying both sides of this equation by , we can conclude that
(7)
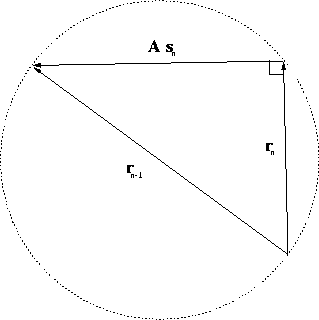
which means that the new residual is orthogonal to the corresponding
step in the residual space. This situation is schematically shown in
Figure 1. Second, substituting formula (6) into
(5), we can conclude that the new residual decreases according
to
(8)
(``Pythagoras's theorem'' ), unless and are orthogonal. These two conclusions are the basic features of
optimization by the method of steepest descent. They will help us
define an improved search direction at each iteration.
dirres
Figure 1 Geometry of the residual in the
data space (a scheme).