




![[*]](http://sepwww.stanford.edu/latex2html/foot_motif.gif) gathered the earthquakes from the IDA network,
an array of about 25 widely distributed gravimeters,
donated by Cecil Green,
and Shearer selected most of the shallow-depth earthquakes
of magnitude greater than about 6 over the 1981-91 time interval,
and sorted them by epicentral distance into bins
gathered the earthquakes from the IDA network,
an array of about 25 widely distributed gravimeters,
donated by Cecil Green,
and Shearer selected most of the shallow-depth earthquakes
of magnitude greater than about 6 over the 1981-91 time interval,
and sorted them by epicentral distance into bins
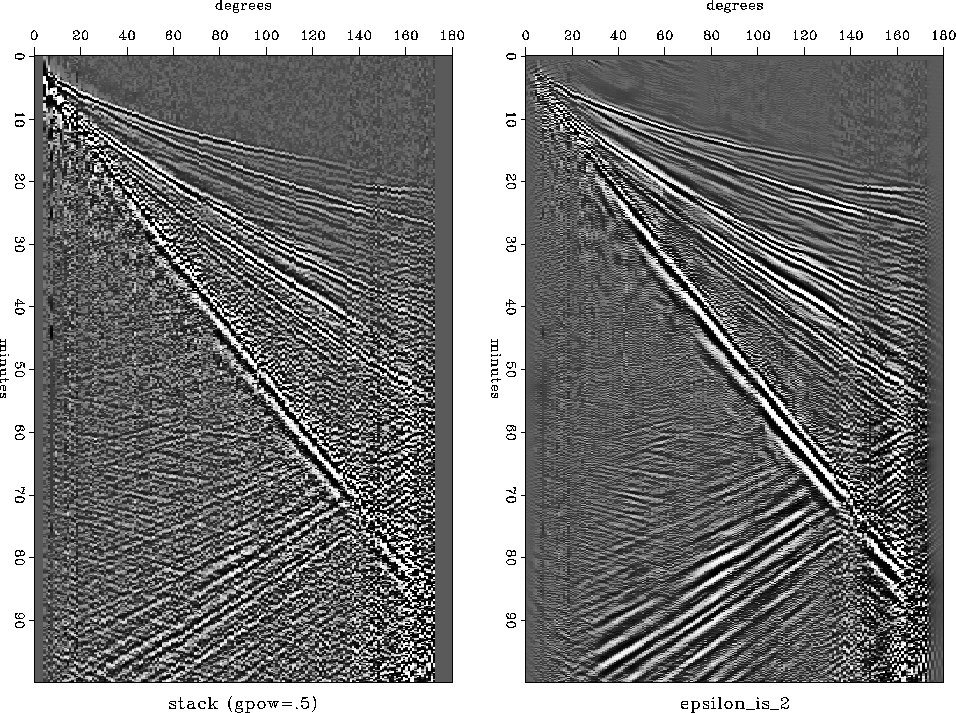
Figure ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) shows a test of noise subtraction
by multidip narrow-pass filtering
on the Shearer-IDA stack.
As with prediction there is a general reduction of the noise.
Unlike with prediction, weak events are preserved
and noise is subtracted from them too.
shows a test of noise subtraction
by multidip narrow-pass filtering
on the Shearer-IDA stack.
As with prediction there is a general reduction of the noise.
Unlike with prediction, weak events are preserved
and noise is subtracted from them too.
 |
Besides the difference in theory,
the separation filters are much smaller
because their size is determined by
the concept that ``two dips will fit anything locally''
(a2=3),
versus the prediction filters
``needing a sizeable window to do statistical averaging.''
The same aspect ratio a1/a2 is kept and
the page is now divided into
11 vertical patches and 24 horizontal patches
(whereas previously the page was divided in ![]() patches).
In both cases the patches overlap about 50%.
In both cases I chose to have about ten times as many equations
as unknowns on each axis in the estimation.
The ten degrees of freedom could be distributed differently
along the two axes, but I saw no reason to do so.
patches).
In both cases the patches overlap about 50%.
In both cases I chose to have about ten times as many equations
as unknowns on each axis in the estimation.
The ten degrees of freedom could be distributed differently
along the two axes, but I saw no reason to do so.
![[*]](http://sepwww.stanford.edu/latex2html/movie.gif)




