




Next: PREDICTION-ERROR FILTER OUTPUT IS
Up: Multidimensional autoregression
Previous: SOURCE WAVEFORM, MULTIPLE REFLECTIONS
Given yt and yt-1, you might like to predict yt+1.
The prediction could be a scaled sum or difference
of yt and yt-1.
This is called ``autoregression''
because a signal is regressed on itself.
To find the scale factors you would optimize the fitting goal below,
for the prediction filter (f1,f2):
filter ! prediction
| ![\begin{displaymath}
\bold 0
\quad \approx \quad
\bold r \eq
\left[
\begin{array...
..._2 \\
y_3 \\
y_4 \\
y_5 \\
y_6 \end{array} \right] \end{displaymath}](img20.gif) |
(9) |
(In practice, of course the system of equations would be
much taller, and perhaps somewhat wider.)
A typical row in the matrix (9)
says that 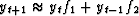 hence the description of f as a ``prediction'' filter.
The error in the prediction is simply the residual.
Define the residual to have opposite polarity
and merge the column vector into the matrix, so you get
hence the description of f as a ``prediction'' filter.
The error in the prediction is simply the residual.
Define the residual to have opposite polarity
and merge the column vector into the matrix, so you get
| ![\begin{displaymath}
\left[
\begin{array}
{c}
0 \\
0 \\
0 \\
0 \\
0...
...
\begin{array}
{c}
1 \\
-f_1 \\
-f_2 \end{array} \right]\end{displaymath}](img22.gif) |
(10) |
which is a standard form for autoregressions and prediction error.
Multiple reflectionsmultiple reflection
are predictable.
It is the unpredictable part of a signal,
the prediction residual,
that contains the primary information.
The output of the filter
(1,-f1, -f2) = (a0, a1, a2)
is the unpredictable part of the input.
This filter is a simple example of
a ``prediction-error'' (PE) filter.
prediction-error filter
filter ! prediction-error
It is one member of a family of filters called ``error filters.''
The error-filter family are filters with one coefficient constrained
to be unity and various other coefficients constrained to be zero.
Otherwise, the filter coefficients are chosen to have minimum power output.
Names for various error filters follow:
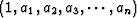 prediction-error (PE) filterprediction-error filter
prediction-error (PE) filterprediction-error filter
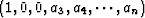 gapped PE filter with a gap
gapped PE filter with a gap
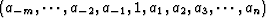 interpolation-error (IE) filterinterpolation-error filter
interpolation-error (IE) filterinterpolation-error filter
filter ! prediction-error
filter ! interpolation-error
We introduce a
free-mask matrix 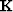 which ``passes'' the freely variable coefficients in the filter
and ``rejects'' the constrained coefficients
(which in this first example is merely the first coefficient a0=1).
which ``passes'' the freely variable coefficients in the filter
and ``rejects'' the constrained coefficients
(which in this first example is merely the first coefficient a0=1).
| ![\begin{displaymath}
\bold K \eq
\left[
\begin{array}
{cccccc}
0 & . & . \\ . & 1 & . \\ . & . & 1
\end{array} \right]\end{displaymath}](img27.gif) |
(11) |
To compute a simple prediction error filter 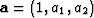 with the CD method,
we write
(9) or
(10) as
with the CD method,
we write
(9) or
(10) as
| ![\begin{displaymath}
\bold 0
\quad \approx \quad
\bold r \eq
\left[
\begin{array...
..._2 \\
y_3 \\
y_4 \\
y_5 \\
y_6 \end{array} \right] \end{displaymath}](img29.gif) |
(12) |
Let us move from this specific fitting goal to the general case.
(Notice the similarity of the free-mask matrix in this filter estimation problem with the
free-mask matrix  in missing data goal (
in missing data goal (![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) ).)
The fitting goal is,
).)
The fitting goal is,
| 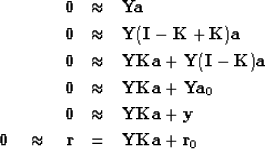 |
(13) |
| (14) |
| (15) |
| (16) |
| (17) |
| (18) |
which means we initialize the residual with
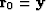 .and then iterate with
.and then iterate with
| 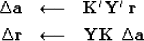 |
(19) |
| (20) |
Next: PREDICTION-ERROR FILTER OUTPUT IS
Up: Multidimensional autoregression
Previous: SOURCE WAVEFORM, MULTIPLE REFLECTIONS
Stanford Exploration Project
4/27/2004