




A program for 2-D convolution with a 1-D convolution program, could convolve with the somewhat long 1-D strip, but it is much more cost effective to ignore the many zeros, which is what we do. We do not multiply by the backside zeros, nor do we even store them in memory. Whereas an ordinary convolution program would do time shifting by a code line like ip=iq-lag, subroutine helicon() ignores the many zero filter values on backside of the tube by using the code ip=iq-lag(ib) where a counter ib ranges over the nonzero filter coefficients. Before subroutine helicon() is invoked, we need to prepare two lists, one list containing nonzero filter coefficients bb(ib), and the other list containing the corresponding lags lag(ib) measured to include multiple wraps around the helix. For example, the 2-D Laplace operator
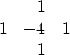 |
(4) |
| |
(5) |
i lag(i) bb(i)
--- ------ -----
1 999 1.0
2 1000 -4.0
3 1001 1.0
4 2000 1.0
Subroutine helicon() did the convolution job for Figure 1.
The second half of subroutine helicon() does adjoint filtering.
The adjoint of filtering is filtering backwards.
[The ends of the 1-D axis are a little tricky
(one end transient, the other truncated)
but the code passes the dot-product test for adjoints
![]() .]
.]
# Polynomial multiplication and its adjoint.
# Designed for gapped filters (helical 2-D, 3-D, etc).
# Requires the filter be causal with an implicit "1." at the onset.
#
subroutine helicon( adjoint, bb,nb, lag, pp,n123, qq )
integer iq, ip, ib, adjoint, nb, lag(nb), n123
real bb(nb), pp(n123), qq(n123)
do ib = 1, nb
if( lag(ib) <= 0 ) call erexit('Filter is non causal')
if( adjoint == 0)
do iq = 1, n123 {
qq(iq) = pp(iq)
do ib = 1, nb { ip = iq - lag(ib)
if( ip < 1 ) break
qq(iq) = qq(iq) + bb(ib) * pp( ip)
}
}
else
do ip = n123, 1, -1 {
pp(ip) = qq(ip)
do ib = 1, nb { iq = ip + lag(ib)
if( iq > n123 ) break
pp(ip) = pp(ip) + bb(ib) * qq( iq)
}
}
return; end
The companion program for deconvolution is virtually identical, except for the obvious differences between equations (1) and (2).