




What I have described above represents my first iteration.
It can be called a
``linear-estimation method."
Next we will try a
``nonlinear-estimation method"
and see that it works better.
If we think of minimizing the relative error in the residual,
then in linear estimation
we used the wrong divisor--that is, we used
the squared data v2 where we should have used
the squared residual ![]() .Using the wrong divisor is roughly justified
when the crosstalk
.Using the wrong divisor is roughly justified
when the crosstalk ![]() is small
because then
v2 and
is small
because then
v2 and ![]() are about the same.
Also, at the outset the residual was unknown,
so we had no apparent alternative to v2,
at least until we found
are about the same.
Also, at the outset the residual was unknown,
so we had no apparent alternative to v2,
at least until we found ![]() .Having found the residual, we can now use it in a second iteration.
A second iteration causes
.Having found the residual, we can now use it in a second iteration.
A second iteration causes ![]() to change a bit,
so we can try again.
I found that,
using the same data as in Figure 1,
the sequence of iterations converged in about two iterations.
to change a bit,
so we can try again.
I found that,
using the same data as in Figure 1,
the sequence of iterations converged in about two iterations.
 |





Figure 2 shows the results of the various weighting methods. Mathematical equations summarizing the bottom row of this figure are:
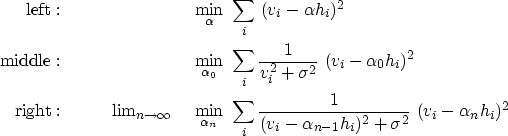 |
(9) | |
| (10) | ||
| (11) |