




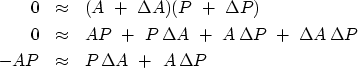 |
(1) | |
| (2) | ||
| (3) |
![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) ,
we need to pack both unknowns into a single vector
x() =
and iner() .
A new aspect is that, to avoid accumulation of errors
from the neglect of the nonlinear product
,
we need to pack both unknowns into a single vector
x() =
and iner() .
A new aspect is that, to avoid accumulation of errors
from the neglect of the nonlinear product
# MISSIF - find MISSing Input data and Filter on 1-axis by min power out.
#
subroutine missif( na, lag, aa, np, pp, known, niter)
integer iter, na, lag, np, niter, nx, ax, px, ip, nr
real pp(np) # input: known data with zeros for missing values.
# output: known plus missing data.
real known(np) # known(ip) vanishes where p(ip) is a missing value.
real aa(na) # input and output: roughening filter
temporary real x(np+na), g(np+na), s(np+na)
temporary real rr(np+na-1), gg(np+na-1), ss(np+na-1)
nr= np+na-1; nx= np+na; px=1; ax=1+np;
call copy( np, pp, x(px))
call copy( na, aa, x(ax))
if( aa(lag) == 0. ) call erexit('missif: a(lag)== 0.')
do iter= 0, niter {
call contran( 0, 0, na,aa, np, pp, rr)
call scaleit ( -1., nr, rr)
call contran( 1, 0, na,aa, np, g(px), rr)
call contran( 1, 0, np,pp, na, g(ax), rr)
do ip= 1, np
if( known(ip) != 0)
g( ip) = 0.
g( lag+np) = 0.
call contran( 0, 0, na,aa, np, g(px), gg)
call contran( 0, 1, np,pp, na, g(ax), gg)
call cgstep( iter, nx, x, g, s, nr, rr, gg, ss)
call copy( np, x(px), pp)
call copy( na, x(ax), aa)
}
return; end
There is a danger that missif() might converge very slowly or fail if aa() and pp() are much out of scale with each other, so be sure you input them with about the same scale. I really should revise the code, perhaps to scale the ``1'' in the filter to the data, perhaps to equal the square root of the sum of the data values.