




The focusing principles can be understood by thinking of a point
diffractor. The seismic response of a point diffractor is an
hyperboloid in 3-D or an hyperbola in 2-D (Z=0). If a CMP gather
is downward continued with the real propagation velocity
(Vm=Vr) to the real point diffractor depth, zr (imaging
condition: t=0s), the diffracted energy is collapsed to the hyperbola
apex and the energy is maximum. The point diffractor position
(xm,ym,Zm) is equal to the point diffractor point at
(xr,yr,zr) (see Figure 1). If the velocity is changed (![]() ) and the CMP is downward continued, the image obtained
at the imaging condition (t=0 s) is not well focused and its energy is
not maximum at the hyperbola apex. For this new velocity, there is a
focusing point, where the energy is maximum at the zero-offset trace,
but its spatial position and depth differ from the real
position.
) and the CMP is downward continued, the image obtained
at the imaging condition (t=0 s) is not well focused and its energy is
not maximum at the hyperbola apex. For this new velocity, there is a
focusing point, where the energy is maximum at the zero-offset trace,
but its spatial position and depth differ from the real
position.
Based on the work of Doherty and Claerbout (1974) and MacKay and Abma (1992), the focusing point depth Zf obtained with migration velocity is equal to the real depth Zr if the migration velocity is equal to the real propagation velocity Vr:
| |
(2) |
| |
(3) |
| |
(4) |
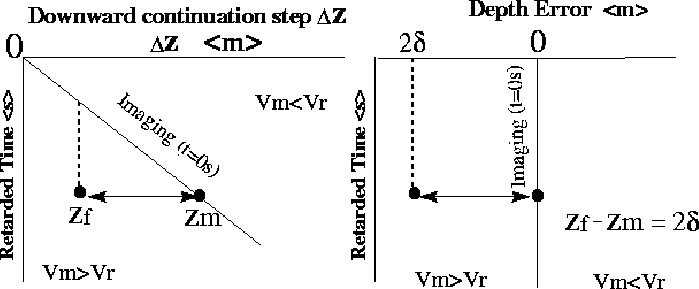
Figure 1 shows the focusing panel and depth error panel. A long the x-axes of
the focusing panel is plotted the downward continuation step,
where every zero-offset trace is chosen. In the
vertical axis is the retarded time ![]() defined by the
recording time, and the vertical time to the current downward
continuation step, divided by the velocity Vm:
defined by the
recording time, and the vertical time to the current downward
continuation step, divided by the velocity Vm:
| |
(5) |
Using the focusing panel and applying the lateral shift defined by the equation (4), the depth error panel is built. Now, the imaging line is the zero error line and the vertical axes is the retarded time. Working with the retarded time allows us to compensate the time shifting between traces of different downward continuation steps Claerbout (1984).
In heterogeneous media focusing analysis fails due to the assumption that the Zm, Zr and Zf are aligned along the same ray path (see Figure 3). To solve this problem Audebert and Diet (1993) suggests correcting the depth focusing panel by residual zero-offset migration with the migration velocity, to obtain a depth focusing panel in agreement with normal incidence ray (in the horizontal layered media it is a vertical path, (see Figure 2). Jeannot and Berranger (1994) suggest making a ray residual migration or a velocity scan of the depth focus panel instead of applying a more expensive zero offset residual migration.
 |
