




Next: 2D Test Cases
Up: Madhav Vyas: Covariance based
Previous: Introduction
The problem of data interpolation can be thought of as re-sampling an image or data set to a lower resolution (everything is known) and then transforming it back to a higher resolution image or data set. To formulate the problem, let us consider that we are trying to estimate a high-resolution image Y(i,j) of dimension 2n  2n from a given low-resolution image X(i,j) of dimension, n n. We assume that the even pixels in the high resolution image (2i,2j) directly come from the pixels of the low-resolution image (i,j)(as given by equation 1). Shaded pixels in Figure
2n from a given low-resolution image X(i,j) of dimension, n n. We assume that the even pixels in the high resolution image (2i,2j) directly come from the pixels of the low-resolution image (i,j)(as given by equation 1). Shaded pixels in Figure ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) correspond to the known pixels and they directly come from the low resolution image.
correspond to the known pixels and they directly come from the low resolution image.
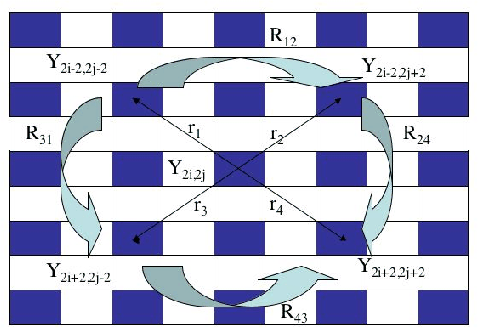
figure1
Figure 1 High resolution image Y, where shaded pixels represent the known values. Rij and rk are elements of matrices quantifying covariance amongst diagonal neighbors and between the central pixel and diagonal neighbors respectively.
|
|  |

Our goal is to determine the odd pixels (2i+1,2j+1). Apart from these two classes of pixels where both the coordinates are either odd or even, we have one more class where one coordinate is odd and one is even ((2i+1,2j) or (2i,2j+1)). Estimating values of these pixels is similar to what is proposed below, but slightly different in terms of geometry of the filter. In seismology, we normally do not have missing rows (time axis), and hence theory developed for determining odd pixels applies directly to seismic data sets.
The value of a missing pixel in image Y is estimated using its four diagonal neighbors and corresponding filter coefficients ( ), as described by equation 2:
), as described by equation 2:
| 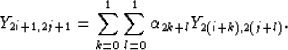 |
(2) |
Geometrically, the filter can be visualized as a convolution template, with 1 at the center and four filter coefficients on the corners. While interpolating, 1 sits on the position of the unknown pixel, and the filter coefficients on corresponding diagonal neighbors.
If we model these images as a locally stationary Gaussian process, according to Weiner filtering theory these interpolation coefficients are given by
| 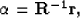 |
(3) |
where is a vector containing filter coefficients, R is the local covariance matrix quantifying covariance between each of the diagonal neighbors, and r is the covariance vector characterizing covariance between the unknown pixel and four diagonal neighbors. Figure displays elements of R and r. We can calculate these matrices for a low-resolution image where all the pixels are known, but we can't directly compute these matrices for the high-resolution image that we desire, since many pixels are unknown. If we assume the statistics to be Gaussian in nature and the sampling distance to be reasonably small, we can approximate high-resolution covariance matrices by low-resolution covariance matrices Li and Orchard (2001). Claerbout (2005) discusses patching technology which can be used to break a section or data cube into multiple overlapping patches or windows, which can be considered stationary. If we consider a window of size M by M, it will have a total of M2 pixels and each pixel will have four neighbors. Let 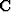 be a 4-by-M2 matrix composed of diagonal neighbors of all the pixels, and
be a 4-by-M2 matrix composed of diagonal neighbors of all the pixels, and 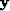 be a vector containing all these pixels; then matrices
be a vector containing all these pixels; then matrices 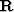 and
and  of equation 3 are given by
of equation 3 are given by
| 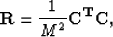 |
(4) |
| 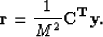 |
(5) |
Substituting these values we get,
| 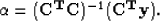 |
(6) |
In short, we first estimate covariance matrices on the low-resolution image and then solve for the filter coefficients. Once we know these filter coefficients, we can slide this filter throughout the image and estimate the missing values; the only condition is that all four legs of this filter should sit on known points. On some occasions we might need to scale the size of the filter up or down (multi-scale) to touch the nearest non-zero diagonal neighbors; this is discussed at length in the section dealing with missing chunks of data.
Lets consider the case of alternating missing columns for the sake of demonstrating the method. The problem of alternate missing columns can be thought of as a problem of increasing the image resolution along one dimension. Let P be a seismic section of dimension 2n 2n with all the odd columns missing. This can be reduced to a section of size 2n n by compressing along the missing axis and removing the missing columns. We can now estimate the covariance values and filter coefficients () on this low-resolution section, and then use these estimates to calculate the pixels belonging to the missing columns as given below,
| 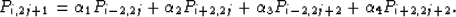 |
(7) |
Notice that in equation 7 we are using pixels spaced one point apart from the missing point along columns and two points apart along rows. This was done to maintain the same directional covariance, since we distorted the image while compressing and throwing away zero values. We need to account for the asymmetry we introduced while estimating the filter coefficients. Whenever we have missing data points and we make a low-resolution image by compressing and throwing away those points, we should always account for the geometry.
Next: 2D Test Cases
Up: Madhav Vyas: Covariance based
Previous: Introduction
Stanford Exploration Project
1/16/2007