




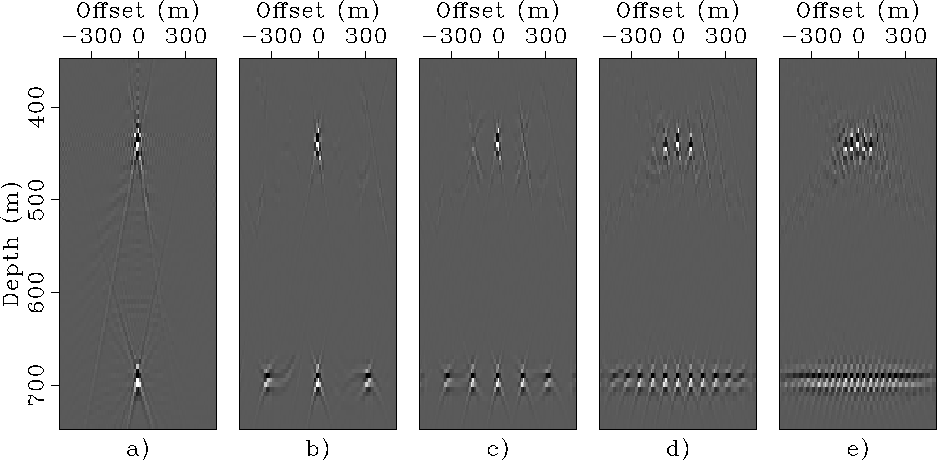
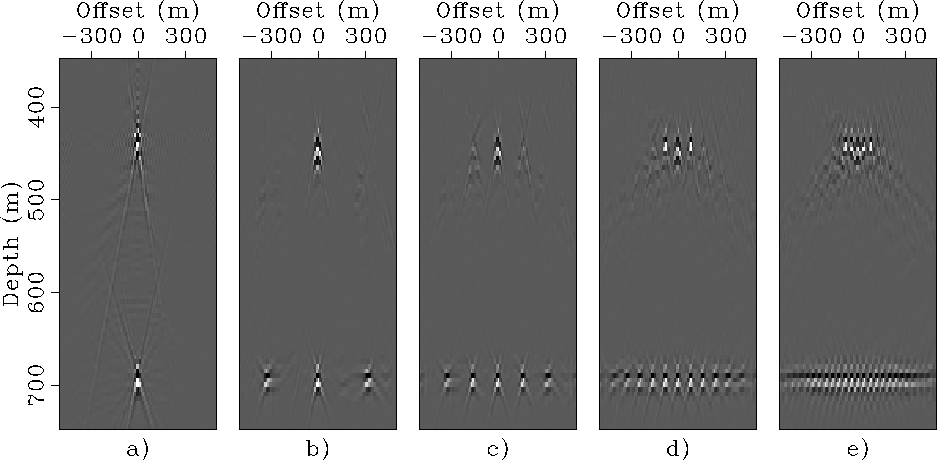
Figure ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) compares
the SODCIG extracted from the starting prestack image
(Figure a)
with the corresponding SODCIGs
extracted from the images obtained by migrating
the four combined data sets with the correct velocity.
All the SODCIGs have been extracted at the
same horizontal location.
As predicted by equation 23,
the images obtained by the combined data sets are affected
by cross talk along the offset domain.
The images obtained from the smaller data set that
had only 8 independent experiments
(Figure e) is
completely degraded by the cross-talk.
Whereas the larger data sets
(
compares
the SODCIG extracted from the starting prestack image
(Figure a)
with the corresponding SODCIGs
extracted from the images obtained by migrating
the four combined data sets with the correct velocity.
All the SODCIGs have been extracted at the
same horizontal location.
As predicted by equation 23,
the images obtained by the combined data sets are affected
by cross talk along the offset domain.
The images obtained from the smaller data set that
had only 8 independent experiments
(Figure e) is
completely degraded by the cross-talk.
Whereas the larger data sets
(![]() equal to 320 and 640 meters)
preserve the velocity information present in the
original SODCIG and allow the computation
of ADCIGs uncontaminated by artifacts,
after the cross-talks are removed by limiting the offset aperture.
equal to 320 and 640 meters)
preserve the velocity information present in the
original SODCIG and allow the computation
of ADCIGs uncontaminated by artifacts,
after the cross-talks are removed by limiting the offset aperture.
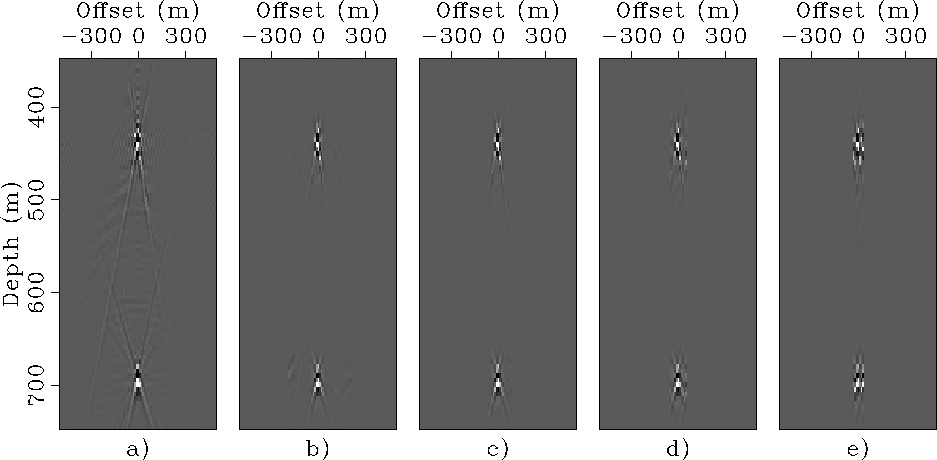
Figure
shows the same SODCIGs
shown in Figure
after the larger subsurface offsets are zeroed.
Because the distance between cross-talks decreases with
decreasing ![]() , the windows
around zero offset also decreases in width.
For Figure b the window was 410 meters wide,
for Figure c it was 170 meters wide,
for Figure d it was 110 meters wide,
for Figure e it was 70 meters wide.
, the windows
around zero offset also decreases in width.
For Figure b the window was 410 meters wide,
for Figure c it was 170 meters wide,
for Figure d it was 110 meters wide,
for Figure e it was 70 meters wide.
 |
 |
after zeroing the larger subsurface offsets
to maximally eliminate the cross-talk
before transformation to angle domain
(Figure ).
Figure shows the ADCIGs obtained
by transforming into the angle domain the SODCIGs shown
Figure .
The ADCIGs computed by imaging
the larger data sets
(![]() equal 320 and 640 meters)
preserve the velocity information contained in the
original ADCIG
(Figure a),
whereas the ADCIG computed from the data set with only
8 independent experiments
(Figure e),
is completely overwhelmed by artifacts.
equal 320 and 640 meters)
preserve the velocity information contained in the
original ADCIG
(Figure a),
whereas the ADCIG computed from the data set with only
8 independent experiments
(Figure e),
is completely overwhelmed by artifacts.
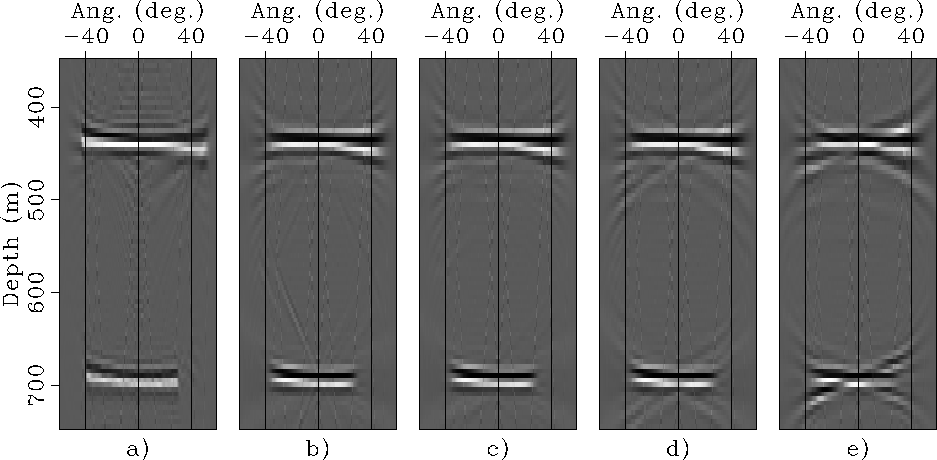 |
.
Panel a): ADCIG computed from source-receiver
migration of synthetic data set migrated with correct velocity.
Panels b) to e): ADCIGs obtained from the migration of data sets
modeled using the proposed method, with respectively
The amount of interference caused by the cross-talk also depends
on how well the SODCIGs are focused around zero subsurface offset,
in addition to the spacing between SODCIGs.
When the initial migration is not perfectly focused because of
velocity inaccuracies, more experiments are needed to preserve
the velocity information than when the starting image is well focused.
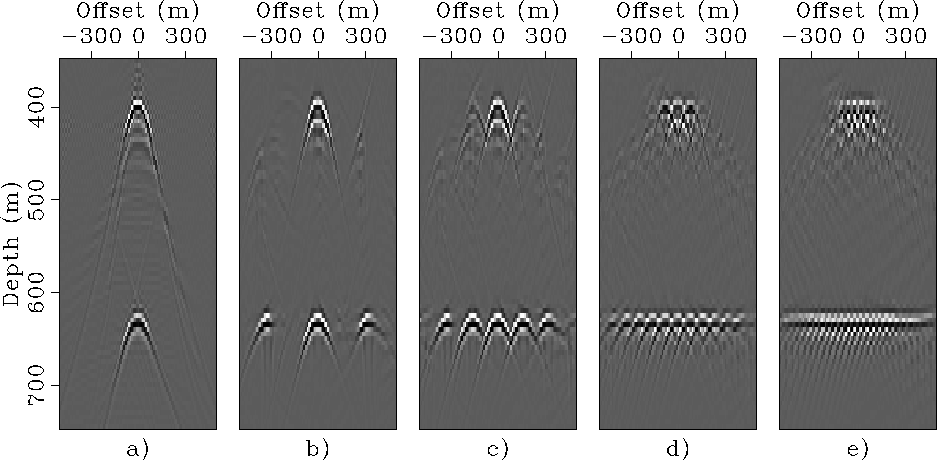
Figure , illustrating this concept,
shows the SODCIGs obtained starting from the prestack
image computed by source-receiver migration using a migration velocity
too low by 10%.
Figure shows the original SODCIG,
whereas the other panels show the SODCIG obtained with increasingly
smaller data sets, as in Figure .
Because of the velocity error the SODCIGs are
not well focused at zero offset.
In this case,
only the data set
with 64 independent experiments produces a SODCIG with the cross-talk
sufficiently separated from zero offset not to interfere
with the desired image.
This result is confirmed by the transformation to angle domain.
Figure shows
the ADCIGs obtained after windowing the SODCIGs shown
in Figure .
The ADCIG obtained by migrating
all the 64 independent experiments
(Figure b)
contains the same velocity information as the
original ADCIG
(Figure a),
whereas the others are affected by artifact caused by the cross talks,
increasingly so going from left to right in the figure.
 |
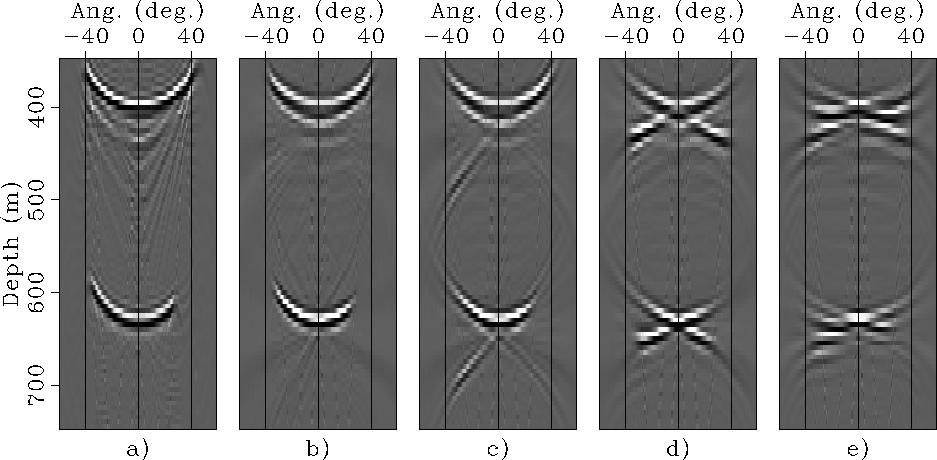 |
after windowing.
Panel a): ADCIG computed from source-receiver
migration of synthetic data set migrated with velocity too slow by 10%.
Panels b) to e): ADCIGs obtained from migration of data sets
modeled using the proposed method, with respectively
The two previous examples display the imaging results when the
modeling and migration velocity were the same.
However, because the proposed modeling method would be used for MVA,
which requires iterative
migrations with different velocities,
it is useful to evaluate the results
when the modeling and migration velocities differ.
Therefore, I modeled four data sets,
again with decreasing ![]() ;I started as before with
;I started as before with
![]() =
640 meters, and went down to 320 meters, 160 meters and 80 meters.
The starting image was obtained by source-receiver migration
with velocity too slow by 10%.
The data were modeled assuming the same low velocity,
but they were migrated using the correct velocity,
and thus the SODCIGs after migration are
now well focused.
=
640 meters, and went down to 320 meters, 160 meters and 80 meters.
The starting image was obtained by source-receiver migration
with velocity too slow by 10%.
The data were modeled assuming the same low velocity,
but they were migrated using the correct velocity,
and thus the SODCIGs after migration are
now well focused.
Figure
shows the resulting SODCIGs and compares them
with the well-focused SODCIGs obtained by source-receiver
migration of the original data set with the correct velocity
(Figure a).
As in Figure ,
the cross-talk artifacts
in the SODCIGs obtained by migrating the data sets formed
by 32 and 64 independent experiments are sufficiently far
from zero offset to be easily zeroed before transformation
to angle domain.
Figure shows
the corresponding ADCIGs, which show flat moveout for
the deep flat reflector.
A small residual moveout can be observed for the shallow dipping reflector
that is probably related to staircase artifacts in the initial modeling.
In other words, because of the coarseness of the modeling grid,
the dipping reflector behaves
as a sequence of short segments of flat reflectors,
instead as a continuous planar reflector dipping at 10 degrees.
All ADCIGs, except the ones shown in
Figure d and e are free from artifacts and provide useful
velocity information.
The last example illustrates the idea that
the interference between SODCIGs depends
on the amount of focusing of the SODCIG after migration,
not in the starting image.
In other words,
the ``residual propagation'' operator
![]() present in
equation 22
may decrease, or increase, the amount of cross-talk artifacts,
depending whether
it improves, or degrades, the focusing of the image.
present in
equation 22
may decrease, or increase, the amount of cross-talk artifacts,
depending whether
it improves, or degrades, the focusing of the image.
 |
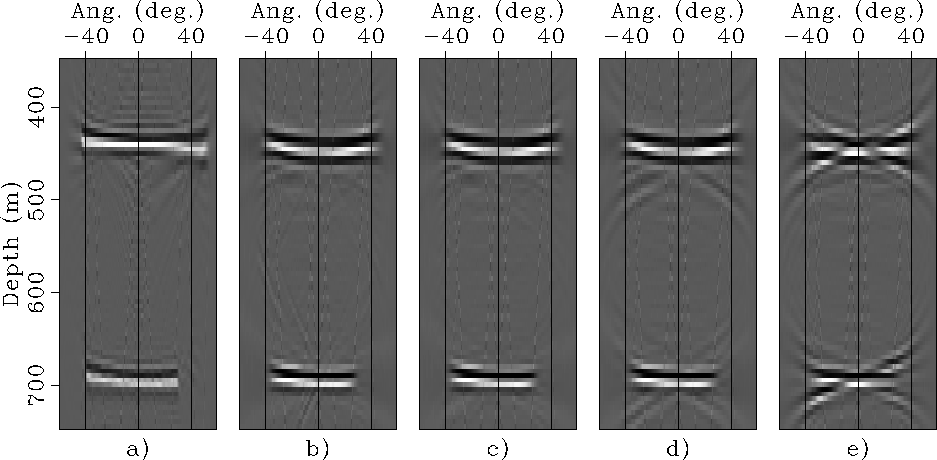 |
after windowing.
Panel a): ADCIG computed from source-receiver
migration of synthetic data set migrated with velocity too slow by 10%.
Panels b) to e): ADCIGs obtained from migration of data sets
modeled using the proposed method, with respectively




