




| |
(13) | |
| (14) |
| |
(15) | |
| (16) |
Figure 7 (left) shows ocean depth measured by a Seabeam apparatus.
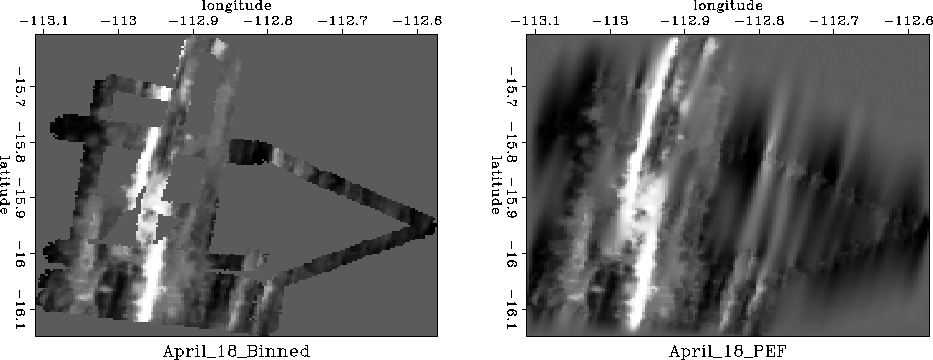 |

Locations not surveyed are evident as the homogeneous gray area.
Using a process akin to ``blind deconvolution'' a
2-D prediction error filter ![]() is found.
Then missing data values are estimated and shown on the right.
Preconditioning with the helix speeded this estimation by a factor of about 30.
The figure required a few seconds of calculation for about 105 unknowns.
is found.
Then missing data values are estimated and shown on the right.
Preconditioning with the helix speeded this estimation by a factor of about 30.
The figure required a few seconds of calculation for about 105 unknowns.
Here is how I came to the helix: For estimation theory to be practical in reflection seismology, I felt I needed a faster solution to simple problems like the Seabeam empty-bin problem. To test the idea of a preconditioner using two-dimensional polynomial division, I first coded it with the ``1.0'' in the corner. Then when I tried to put the ``1.0'' on the side where it belongs (see (6)), I could not adequately initialize the filter at the boundaries until I came upon the idea of the helix. I had never set out to solve the problem of stability of multidimensional feedback filtering (which I believed to be impossibly difficult). Serendipity.
This example suggests that the philosophy of image creation by optimization has a dual orthonormality: First, Gauss (and common sense) tells us that the data residuals should be roughly equal in size. Likewise in Fourier space they should be roughly equal in size, which means they should be roughly white, i.e. orthonormal. (I use the word ``orthonormal'' because white means the autocorrelation is an impulse, which means the signal is statistically orthogonal to shifted versions of itself.) Second, to speed convergence of iterative methods, we need a whiteness, another orthonormality, in the solution. The map image, the physical function that we seek, might not be itself white, so we should solve first for another variable, the whitened map image, and as a final step, transform it to the ``natural colored'' map.
Often geophysicists create a preconditioning matrix ![]() by inventing columns that ``look like'' the solutions that they seek.
Then the space
by inventing columns that ``look like'' the solutions that they seek.
Then the space ![]() has many fewer components
than the space of
has many fewer components
than the space of ![]() .This approach is touted as a way of introducing
geological and geophysical prior information into the solution.
Indeed, it strongly imposes the form of the solution.
This approach is more like ``curve fitting'' than ``inversion.''
My preferred approach is
not to invent the columns of the preconditioning matrix,
but to estimate the prediction-error filter of the model and use its inverse.
.This approach is touted as a way of introducing
geological and geophysical prior information into the solution.
Indeed, it strongly imposes the form of the solution.
This approach is more like ``curve fitting'' than ``inversion.''
My preferred approach is
not to invent the columns of the preconditioning matrix,
but to estimate the prediction-error filter of the model and use its inverse.