




Figure ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) shows a day's worth of data
shows a day's worth of data![[*]](http://sepwww.stanford.edu/latex2html/foot_motif.gif) collected at sea by SeaBeam,
an apparatus for measuring water depth both
directly under a ship, and somewhat off to the sides of the ship's track.
The data is measurements of depth h(x,y) at miscellaneous locations
in the (x,y)-plane.
collected at sea by SeaBeam,
an apparatus for measuring water depth both
directly under a ship, and somewhat off to the sides of the ship's track.
The data is measurements of depth h(x,y) at miscellaneous locations
in the (x,y)-plane.
|
seabin90
Figure 8 Depth of the ocean under ship tracks. Empty bins are displayed with an average depth | 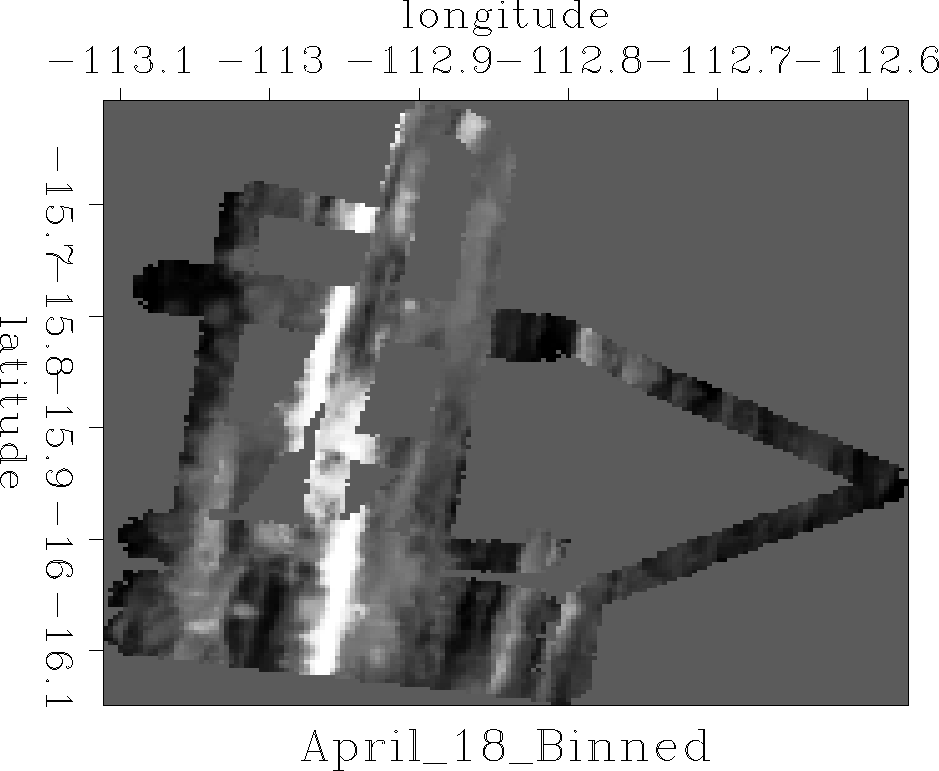 |





The locations are scattered about,
according to various aspects
of the ship's navigation and the geometry of the SeaBeam sonic antenna.
Figure was made by binning with
bin2()
and equation ().
The spatial spectra of the noise in the data
could be estimated where tracks cross over themselves.
This might be worth while, but we do not pursue it now.
Here we focus on the empty mesh locations where no data is recorded
(displayed with the value of the mean depth ![]() ).
These empty bins were filled with
module mis2 .
Results are in Figure .
).
These empty bins were filled with
module mis2 .
Results are in Figure .
 |
![[*]](http://sepwww.stanford.edu/latex2html/movie.gif)
In Figure the left column results from 20 iterations
while the right column results from 100 iterations.
The top row in Figure shows that more iterations
spreads information further into the region of missing data.
It turned out that the original method strictly honoring known data
gave results so similar to the second method (regularizing)
that the plots could not be visually distinguished.
The middle row in Figure therefore shows
the difference in the result of the two methods.
We see an outline of the transition between known and unknown regions.
Obviously, the missing data is pulling known data towards zero.
The bottom row in Figure shows that preconditioning
spreads information to great distances much quicker
but early iterations make little effort to honor the data.
(Even though these results are for ![]() .)
Later iterations make little change at long distance
but begin to restore sharp details on the small features
of the known topography.
.)
Later iterations make little change at long distance
but begin to restore sharp details on the small features
of the known topography.
What if we can only afford 100 iterations?
Perhaps we should first do 50 iterations with
preconditioning to develop the remote part of the solution and
then do 50 iterations by one of the other two methods to be sure
we attended to the details near the known data.
A more unified approach (not yet tried, as far as I know)
would be to unify the techniques.
The conjugate direction method searches two directions,
the gradient and the previous step.
We could add a third direction,
the smart direction of equation (14).
Instead of having a ![]() matrix
solution like equation () for two distances,
we would need to solve a
matrix
solution like equation () for two distances,
we would need to solve a ![]() matrix for three.
matrix for three.
Figure has a few artifacts connected with the
use of the helix derivative.
Examine equation () to notice the shape of the helix derivative.
In principle, it is infinitely long in the horizontal axis
in both equation () and Figure .
In practice, it is truncated. The truncation is visible as bands
along the sides of Figure .
As a practical matter, no one would use the first two bin filling methods
with helix derivative for the roughener
because it is theoretically equivalent to the gradient operator
![]() which has many fewer coefficients.
Later, in Chapter
we'll find a much smarter roughening operator
which has many fewer coefficients.
Later, in Chapter
we'll find a much smarter roughening operator ![]() called the Prediction Error Filter (PEF)
which gives better results.
called the Prediction Error Filter (PEF)
which gives better results.