




![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) shows a bottom-sounding survey
of the Sea of Galilee
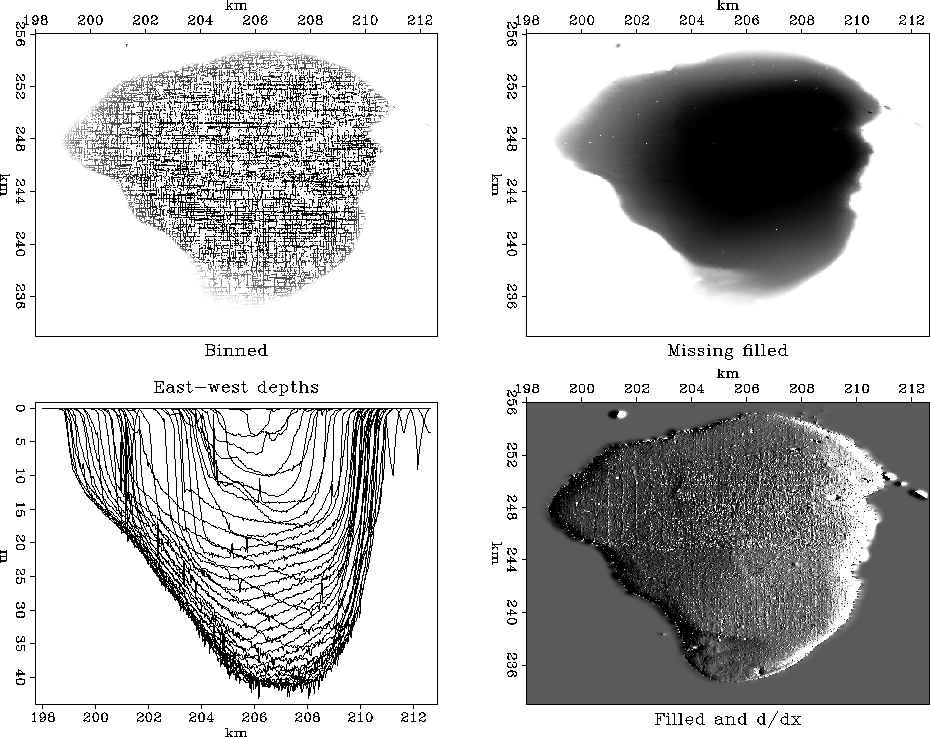
shows a bottom-sounding survey
of the Sea of Galilee![[*]](http://sepwww.stanford.edu/latex2html/foot_motif.gif) at various stages of processing.
The ultimate goal is not only a good map of
the depth to bottom,
but images useful for the purpose
of identifying archaeological, geological, or
geophysical details of the sea bottom.
The Sea of Galilee is unique
because it is a fresh-water lake below sea-level.
It seems to be connected to the great rift (pull-apart)
valley crossing east Africa.
We might delineate the Jordan River delta.
We might find springs on the water bottom.
We might find archaeological objects.
at various stages of processing.
The ultimate goal is not only a good map of
the depth to bottom,
but images useful for the purpose
of identifying archaeological, geological, or
geophysical details of the sea bottom.
The Sea of Galilee is unique
because it is a fresh-water lake below sea-level.
It seems to be connected to the great rift (pull-apart)
valley crossing east Africa.
We might delineate the Jordan River delta.
We might find springs on the water bottom.
We might find archaeological objects.
 |
![[*]](http://sepwww.stanford.edu/latex2html/movie.gif)





The raw data is 132,044 triples, (xi,yi,zi),
where xi ranges over about 12 km and
where yi ranges over about 20 km.
The lines you see in Figure
are sequences of data points, i.e., the track of the survey vessel.
The depths zi are recorded to an accuracy of about 10 cm.
The first frame in Figure shows simple binning.
A coarser mesh would avoid the empty bins but lose resolution.
As we refine the mesh for more detail,
the number of empty bins grows
as does the care needed in devising a technique
for filling them.
This first frame uses the simple idea from Chapter of
spraying all the data values to the nearest bin
with bin2()
and dividing by the number in the bin.
Bins with no data obviously need to be filled in some other way.
I used a missing data program like that in the recent section
on ``wells not matching the seismic map.''
Instead of roughening with a Laplacian, however,
I used the gradient operator igrad2
The solver is grad2fill().
grad2filllow cut missing data
The output of the roughening operator is an image, a filtered version of the depth, a filtered version of something real. Such filtering can enhance the appearance of interesting features. For example, scanning the shoreline of the roughened image (after missing data was filled), we see several ancient shorelines, now submerged.
| The adjoint is the easiest image to build. The roughened map is often more informative than the map itself. |
The views expose several defects of the data acquisition and of our data processing. The impulsive glitches (St. Peter's fish?) need to be removed but we must be careful not to throw out the sunken ships along with the bad data points. Even our best image shows clear evidence of the recording vessel's tracks. Strangely, some tracks are deeper than others. Perhaps the survey is assembled from work done in different seasons and the water level varied by season. Perhaps some days the vessel was more heavily loaded and the depth sounder was on a deeper keel. As for the navigation equipment, we can see that some data values are reported outside the lake!
We want the sharpest possible view of this classical site. A treasure hunt is never easy and no one guarantees we will find anything of great value but at least the exercise is a good warm-up for submarine petroleum exploration.