




The basic form of the inversion is the same as that
used in chapter ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) ,
where the inversion for the noise
,
where the inversion for the noise ![]() from the regression
from the regression
![]() is stabilized by assuming that the noise is approximately
the noise estimated from the prediction-error filtering result
is stabilized by assuming that the noise is approximately
the noise estimated from the prediction-error filtering result ![]() .These are combined to produce the system
.These are combined to produce the system
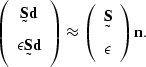 |
(83) |
If ![]() is substituted for
is substituted for ![]() in the above system of regressions,
and the unknown missing data
in the above system of regressions,
and the unknown missing data ![]() is moved to the right side,
the system becomes
is moved to the right side,
the system becomes
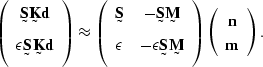 |
(84) |
This system might be further modified to account for the areas in the data where the prediction-error filtering result is not expected to produce a good estimate of the result. For isolated missing data samples, the change in the result is likely to be small, since a single missing sample is can be considered to be noise and will be well predicted. For groups of missing traces, the prediction-error filtering result will not be a good estimate, and the previous system should be modified to ignore the estimate of the missing data in these areas. The emphasis here is recovering small numbers of missing data samples, not interpolation of large gaps in the data. Even so, in the examples to follow, the signal seems to be reasonably extrapolated several traces into an area of missing traces.