|
|
|
|
Selecting the right hardware for Reverse Time Migration |
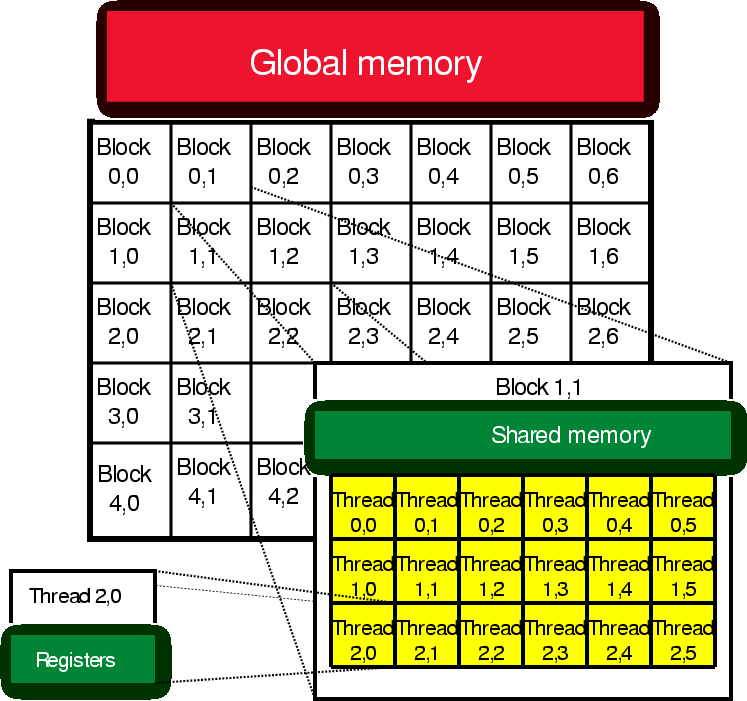
GPGPUs are often referred to as ``streaming processors''. In this context, a streaming paradigm means that the same operation, or set of operations, is performed on a stream of data, a form of Single Instruction Multiple Data (SIMD). A GPGPU is broken into a grid of thread blocks. Ideally, the number of thread blocks is equal to greater than the number of processing units on the GPGPU. Multiple threads, up to 512 on the latest Nvidia GPGPU, are started on each grid block. The threads help hide memory latency. While one thread is waiting for data, another thread can be executing. Each thread block has its own set of registers (fastest memory) and each grid block has a pool of shared memory, which can be as fast to access as register. In addition, there is a large pool of global memory (4GB on the latest Nvidia GPGPU). This global memory has latency two orders of magnitude larger than accessing registers or shared memory. Figure 4 shows this two level parallelism.
|
|---|
|
gpgpu
Figure 4. The memory hierarchy of typical GPGPU. The processing elements are broken into a 2-D grid block. Each 2-D grid block is broken into a grid of thread blocks. Each thread has its own set of registers. Each grid block can access the same shared memory and grid blocks can access the globabl memory.[NR] |
|
|
On the GPGPU, the basic acoustic algorithm shown in algorithm 2 is
broken into two parts. Replacing the unrealistic 4-D source volume with the
previous prev, current pcur, and updated pnext wavefield, the CPU portion of
the code has a form similar to algorithm 3.
![]()
The GPGPU update kernel has nearly as simple a form.

GPGPUs are often considered difficult to program. This is partially due to unfamiliarity with the parallelism model and partially due to the need to explicitly handle transfers to and from the GPGPU and at different levels of GPGPU memory in order to achieve maximum performance. For an unoptimized code, this perspective has validity. An optimized GPGPU code most likely contains less lines and less complexity. Once the relative simplicity of the GPGPU kernel parallelism and memory hierarchy is understood, one could argue that the GPGPU offers a quicker development cycle.
Simply looking at the total memory bandwidth available and the raw compute
power offered, GPUs would seem to be the obvious best compute device for RTM.
Unfortunately, some of the limitations on the programming model and memory hierarchy makes it less
clear.
|
|
|
|
Selecting the right hardware for Reverse Time Migration |