|
|
|
|
Accelerating 3D convolution using streaming architectures on FPGAs |
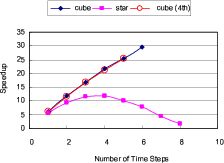
We have implemented the 2nd order `cube' with 6 time steps and the 4th order `cube' with 5 time steps onto the Maxeler acceleration card. The 2nd order `cube' processes 6 time steps in 1.383 seconds, and the 4th order `cube' processes 5 time steps in 1.346 seconds. Compared to the 6.36 seconds to process one time step in 2nd order, the 2nd and 4th order `cube' designs provide 27.5x and 23.5x speedups, slightly lower than our estimated performance.
The speedup discussed so far is achieved by using one FPGA of the acceleration card. The acceleration card contains two FPGAs of the same settings. There is also a inter-FPGA link which can update the overlapping boundaries between the FPGAs in parallel with the computation performed on the FPGAs. Therefore, by dividing the array into two parts and computing in two FPGAs concurrently, we can get another 2x and achieve up to 55x and 47x speedup in total.
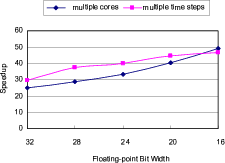
Note that the FPGAs we are using are Xilinx Virtex-5 LX330T chips released several years ago. Projecting our designs into the recently announced Xilinx Virtex-6 SX475T FPGAs (shown in Table 1), we can fit up to 13 time steps in one FPGA and achieve up to 55x speedup. With two FPGAs working concurrently on an acceleration card, we can achieve up to 110x speedup compared to a single-core CPU version.
|
multiple-timesteps
Figure 5. Speedups for processing different number of time steps processed in one pass. |
|
|---|---|
|
|
|
float-prec
Figure 6. Speedups for different floating-point precisions. |
|
|---|---|
|
|
|
|
|
|
Accelerating 3D convolution using streaming architectures on FPGAs |