




Instead of L2-norm solutions obtained by the conventional LS solution,
Lp-norm minimization solutions, with ![]() , are often tried.
Iterative inversion algorithms called IRLS
(Iteratively Reweighted Least Squares)
algorithms have been developed to solve these problems, which lie
between the least-absolute-values problem and the classical least-squares problem.
The main advantage of IRLS is to provide an easy way to compute
the approximate L1-norm solution.
L1-norm solutions are known to be more robust than L2-norm solutions,
being less sensitive to spiky, high-amplitude noise Claerbout and Muir (1973); Scales et al. (1988); Scales and Gersztenkorn (1987); Taylor et al. (1979).
, are often tried.
Iterative inversion algorithms called IRLS
(Iteratively Reweighted Least Squares)
algorithms have been developed to solve these problems, which lie
between the least-absolute-values problem and the classical least-squares problem.
The main advantage of IRLS is to provide an easy way to compute
the approximate L1-norm solution.
L1-norm solutions are known to be more robust than L2-norm solutions,
being less sensitive to spiky, high-amplitude noise Claerbout and Muir (1973); Scales et al. (1988); Scales and Gersztenkorn (1987); Taylor et al. (1979).
The problem solved by IRLS is a minimization of the weighted residual in the least-squares sense :
| (5) |
| (6) |
| (7) |
| (8) |
![]()
![]()
IRLS can be easily incorporated in CG algorithms by including
a weight ![]() such that the operator
such that the operator ![]() has a postmultiplier
has a postmultiplier ![]() and the the adjoint operator
and the the adjoint operator ![]() has a premultiplier
has a premultiplier ![]() Claerbout (2004).
Even though we do not know the real Lp-norm residual vector
at the beginning of the iteration,
we can approximate the residual with a residual
of the previous iteration step, and it will converge to
a residual that is very close to the Lp-norm residual as the iteration step continues.
This can be summarized as follows:
Claerbout (2004).
Even though we do not know the real Lp-norm residual vector
at the beginning of the iteration,
we can approximate the residual with a residual
of the previous iteration step, and it will converge to
a residual that is very close to the Lp-norm residual as the iteration step continues.
This can be summarized as follows:
iterate {
![$\bold W \quad\longleftarrow\quad{\bf diag}[f(\bold r)]$](img32.gif)
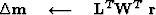

}.