




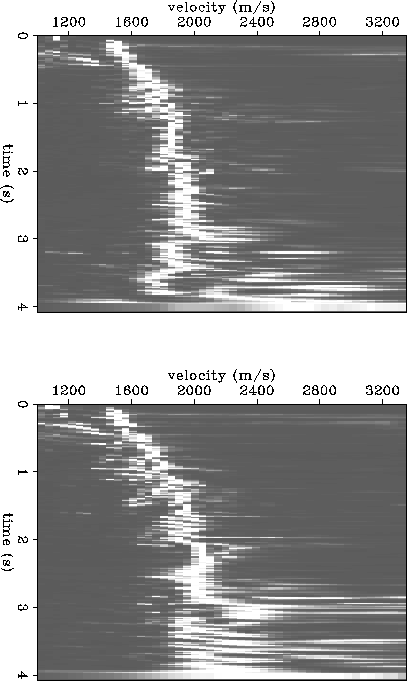
Figure ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) shows two migration velocity semblance panels. The top
panel corresponds to the surface location at x = 4 km, and the bottom
panel to x = 4.7 km. Figure contains the same information,
but is plotted in contours as opposed to raster. At this point,
I have not spent any extra effort
trying to fine-tune the migration velocity algorithm. Already, however,
the migration velocity spectrum looks better resolved than the stacking
velocity spectrum, especially when comparing the contour plots of
Figure to Figure . Still, there is considerable
migration semblance smear, and I need to fine-tune the algorithm.
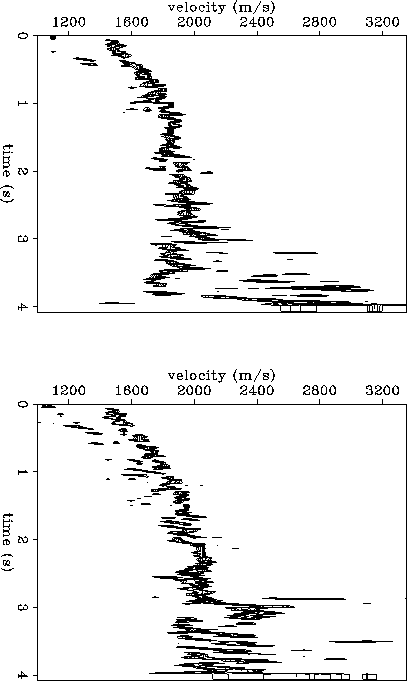
shows two migration velocity semblance panels. The top
panel corresponds to the surface location at x = 4 km, and the bottom
panel to x = 4.7 km. Figure contains the same information,
but is plotted in contours as opposed to raster. At this point,
I have not spent any extra effort
trying to fine-tune the migration velocity algorithm. Already, however,
the migration velocity spectrum looks better resolved than the stacking
velocity spectrum, especially when comparing the contour plots of
Figure to Figure . Still, there is considerable
migration semblance smear, and I need to fine-tune the algorithm.
Currently, the main computational core of the CM code is running at about 420 Mflop/s on 8k processors. A prestack migration velocity analysis of 32 48-fold CMP gathers, 2,000 samples per trace, with 48 stacking velocities and 256 output time samples, requires a total of about 255 cpu seconds on 4k processors. About 30 s of that time is required to read input data from an NFS mounted disk to the front-end memory, another 10 s to transfer the data from the front-end to the CM, about 210 s to do the computations within the CM, and about 5 seconds to write the results from the CM to front-end to disk. As opposed to the stacking velocity analysis algorithm, the migration velocity analysis is mostly cpu bound, since I/O requires only about 18% of the total run time. Addition of a data vault or fast disk array will only speed the migration velocity analysis by a factor of about 1.2x.
 |

 |