




The elements of the ith row of the Galerkin operator are given by evaluation of the function a(Nj,Ni) for all N-j. These elements are only non-zero for those basis functions whose support overlaps that of the function Ni. The only nodal basis functions that need to be considered are those that share a common element with the ith node.
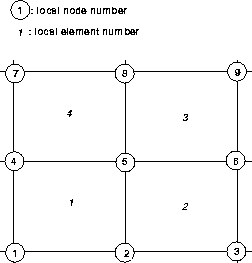 |

If the local numbering scheme shown in
Figure ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) is used, then we can clearly see that there are
only nine non-zero elements in each row. Each node in the mesh has a
nine-vector of operator coefficients associated with it. These vectors
can be calculated in parallel for each node in the mesh,
is used, then we can clearly see that there are
only nine non-zero elements in each row. Each node in the mesh has a
nine-vector of operator coefficients associated with it. These vectors
can be calculated in parallel for each node in the mesh,
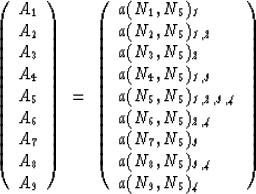
To calculate the operator elements for the nodes, I must know whether the neighboring nodes exist, to account for boundary nodes, and the (x,y) coordinates of the neighboring nodes. At this stage the connectivity of the nodes enters the problem. The coordinate information is stored as an array on the CM. Each processor (or virtual processor) is responsible for calculating one row of the Galerkin operator and one element of the RHS of the equation. To do this, it must gather information about the coordinates of its eight neighboring nodes.
If the nodes are connected in a regular 2-D mesh, the coordinates can be stored in a 2-D array. The array will be mapped onto the processors of the CM with neighboring elements in the array stored in neighboring processors (or the same processor if there are more array elements than processors). The transfer of coordinates from each node to its neighbors is a simple ``shift'' operation. Eight shifts, each by one element, are sufficient to gather all the information needed to construct the row of the operator for each node.
If the nodes are not connected in a regular 2-D mesh, the transfer of coordinate information is more complicated. To gather the coordinate information, each processor must perform an indexed lookup of the coordinates of its neighbors. This type of data transfer is much less efficient than the simple shift operation. The CM is much better at transferring data when a regular transfer pattern is known at compile time than when it has to perform a global ``send'' operation at run time.
Once the coordinate information has been gathered, the calculation of the rows of the global operator is a fully parallel operation. It is not too important, since the data transfer occurs only once in this process. In my implementation of the method on the CM, the cost of calculating the operator was small compared with the cost of the solution phase. If a higher order FE method were used the cost of assembling the operator might be greater, however, a higher order method produces a more complex operator so the solution phase would also be more expensive.
After the operator has been calculated the boundary conditions are applied. For essential boundary conditions, this merely involves zeroing elements of the operator. The boundary information is distributed across all the nodes so the operation can be performed in parallel. The natural boundary conditions require no modification of the operator because it is implicit in the FE method. More complex boundary conditions usually involve modification of the operator and/or the RHS. These will also be parallel computations.