|
|
|
|
Accelerating 3D convolution using streaming architectures on FPGAs |
Finite difference based convolution operators normally perform multiplications and additions on a number of adjacent points. While the points are neighbors to each other in a 3D geometric perspective, they are often stored relatively far apart in memory. For example,
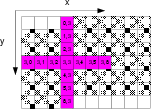
in the 7-point 2D convolution performed on a 2D array shown in Figure
1, data items ![]() and
and ![]() are neighbors
in the
are neighbors
in the ![]() direction. However, suppose the array uses a row-major
storage and has a row size of 512, the storage locations of
direction. However, suppose the array uses a row-major
storage and has a row size of 512, the storage locations of ![]() and
and ![]() will be 512 items (one line) away. For a 3D array of the size
will be 512 items (one line) away. For a 3D array of the size
![]() , the neighbors in
, the neighbors in ![]() direction will be
direction will be ![]() items away. In software implementations, this memory storage pattern can incur a lot of cache misses when the domain gets larger, and decreases the efficiency of the computation.
items away. In software implementations, this memory storage pattern can incur a lot of cache misses when the domain gets larger, and decreases the efficiency of the computation.
|
convolution-2D
Figure 1. A streaming example of 2D convolution. |
|
|---|---|
|
|
In an FPGA implementation, we use a streaming architecture that computes one result per cycle. As shown in Figure 1, suppose we are applying the stencil on the data item ![]() , the circuit requires 13 different values (solid, dark-color), two of which (
, the circuit requires 13 different values (solid, dark-color), two of which (![]() and
and ![]() ) are three lines away from the current data item. As the data items are streamed in one by one, in order to make the values of
) are three lines away from the current data item. As the data items are streamed in one by one, in order to make the values of ![]() and
and ![]() available to the circuit, we put a memory buffer that stores all the six lines of values from
available to the circuit, we put a memory buffer that stores all the six lines of values from ![]() to
to ![]() (illustrated by the checker board pattern on the
grid). For a row size of 512, this incurs a storage cost of
(illustrated by the checker board pattern on the
grid). For a row size of 512, this incurs a storage cost of ![]() data items.
data items.
Similarly, for a 7-point 3D convolution on a
![]() array, the design requires a buffer for
array, the design requires a buffer for
![]() data items. Assume each data item is a single-precision floating-point number, the buffer size amounts to 6 MB for the
data items. Assume each data item is a single-precision floating-point number, the buffer size amounts to 6 MB for the
![]() example. The FPGA chip we currently use provides 1.4 MB of potential buffer size, which is not enough to store all the streamed-in values. We solve this problem by 3D blocking, i.e. dividing the original 3D array into smaller-size 3D arrays, and performing convolution on them separately.
example. The FPGA chip we currently use provides 1.4 MB of potential buffer size, which is not enough to store all the streamed-in values. We solve this problem by 3D blocking, i.e. dividing the original 3D array into smaller-size 3D arrays, and performing convolution on them separately.
3D blocking reduces the buffer requirement for an FPGA convolution implementation at a cost. Given a convolution stencil with ![]() non-zero lags in each direction, we must send in a
non-zero lags in each direction, we must send in a
![]() block to produce a
block to produce a
![]() output block. As
output block. As ![]() ,
, ![]() ,
, ![]() becomes small, the blocking overhead can dominate. Meanwhile, the initialization cost for setting up the memory address registers and start the streaming process is also increased as we need to stream multiple blocks.
becomes small, the blocking overhead can dominate. Meanwhile, the initialization cost for setting up the memory address registers and start the streaming process is also increased as we need to stream multiple blocks.
|
|
|
|
Accelerating 3D convolution using streaming architectures on FPGAs |