 Note
NoteThe Intel® OpenMP* runtime library has the ability to bind OpenMP threads to physical processing units. The interface is controlled using the KMP_AFFINITY environment variable. Depending on the system topology, application, and operating system, thread affinity can have a dramatic effect on the application speed.
NoteLinux only. For Cluster OpenMP*, this environment variable applies individually to each process created by the run-time system, and global thread IDs are contiguous within each process and across all processes. An individual system topology map and message listing is created for each process.
The KMP_AFFINITY environment variable uses the following general syntax:
Syntax |
|---|
|
KMP_AFFINITY=[<modifier>,...]<type>[,<permute>][,<offset>] |
The following table describes the supported specific arguments.
| Argument |
Default |
Description |
|---|---|---|
|
modifier |
noverbose respect granularity=core |
Optional. String consisting of keyword and specifier.
|
|
type |
none |
Required string. Indicates the thread affinity to use.
The logical and physical types are deprecated but supported for backward compatibility. |
|
permute |
0 |
Optional. Positive integer value. |
|
offset |
0 |
Optional. Positive integer value. |
Type is the only required argument.
Does not bind OpenMP threads to particular thread contexts; however, if the operating system supports affinity, the compiler still uses the OpenMP thread affinity interface to determine system topology.
Specify KMP_AFFINITY=verbose,none to list a system topology map.
Specifying compact binds the OpenMP thread <n>+1 on a free thread context as close as possible to the thread context where the <n> OpenMP thread was bound. For example, in a topology map the nearer a node is to the root, the more significance the node has when sorting the threads.
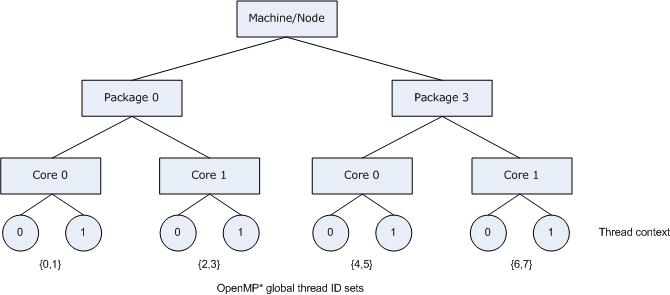
The following figure illustrates the topology for a system with two processors, and each processor has two cores; further, each core has Hyper-Threading Technology (HT Technology) enabled.
The following figure also illustrates the binding of OpenMP thread to hardware thread contexts when specifying KMP_AFFINITY=granularity=fine,compact.
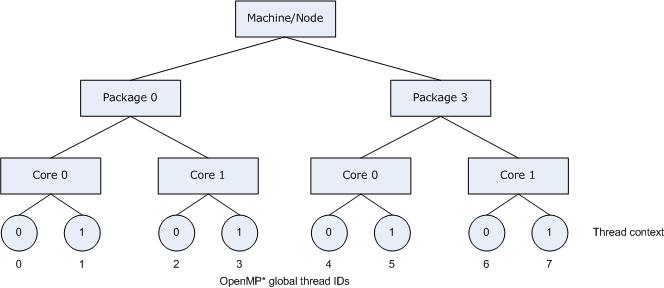
On IA-32 and Intel® 64 architectures, if the package has an APIC (Advanced Programmable Interrupt Controller) the compiler will use the cpuid instruction to obtain the package ID, core ID, and thread context ID. Under normal conditions each thread context on the machine is assigned a unique APIC ID at boot time. Normally, core IDs on a package and thread context IDs on a core are contiguous; however, numbering assignment gaps are common for package IDs, as shown in the figure above.
On IA-64 architectures on Linux*, the compiler uses /proc/cpuinfo. The package ID, core ID, and thread context ID are obtained from the “physical id”, “core id”, and “thread id” fields from /proc/cpuinfo. The core ID and thread context ID default to 0, but the “physical id” field must be present in order to determine the machine topology, which is not always the case.
If the compiler cannot determine the system topology using either method but the operating system supports affinity, a warning message is printed, and the topology is assumed to be flat. For example, a flat topology assumes the operating system processor N maps to package N, and there exists only one thread context per core and only one core for each package. (This assumption is always the case for processors based on IA-64 architecture running Windows.)
Regardless of the method used in determining the machine topology, if there is only one thread context per core for every core on the system, the thread context level will not appear in the topology map. If there is only one core per package for every package in the system, the core level will not appear in the topology map.
The package level will always appear in the topology map, even if there only a single package in the system.
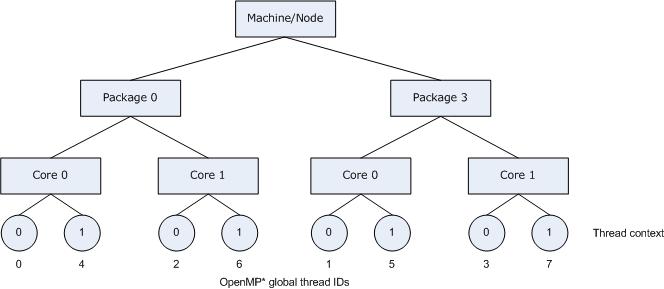
Specifying scatter distributes the threads as evenly as possible across the entire system. scatter is the opposite of compact; so the leaves of the node are most significant when sorting through the system topology map. Specifying scatter on the same system as shown in the figure above, the OpenMP threads would be assigned the thread contexts as shown in the following figure.
The following figure illustrates the result of specifying KMP_AFFINITY=granularity=fine,scatter.
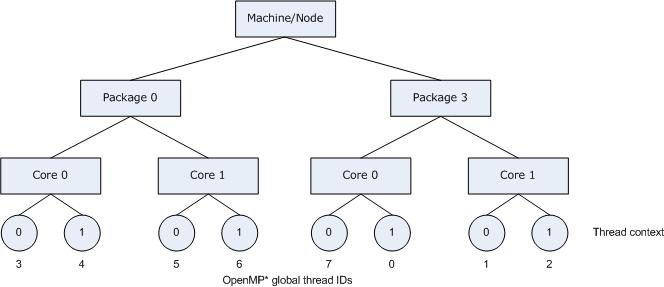
For both compact and scatter, permute and offset are allowed; however, if you specify only one integer, the compiler interprets the value as a permute specifier. Both permute and offset default to 0.
The permute specifier controls which levels are most significant when sorting the system topology map. A value for permute forces the mappings to make the specified number of most significant levels of the sort the least significant, and it inverts the order of significance. The root node of the tree is not considered a separate level for the sort operations.
The offset specifier indicates the starting position for thread assignment.
The following figure illustrates the result of specifying KMP_AFFINITY=granularity=fine,compact,0,3.
Since a thread normally executes faster on a core where it is not competing for resources with another active thread on the same core, you might want to avoid binding multiple threads to the same core while leaving other cores unused. The following figure illustrates this strategy of using KMP_AFFINITY=granularity=fine,compact,1,0 as a setting.
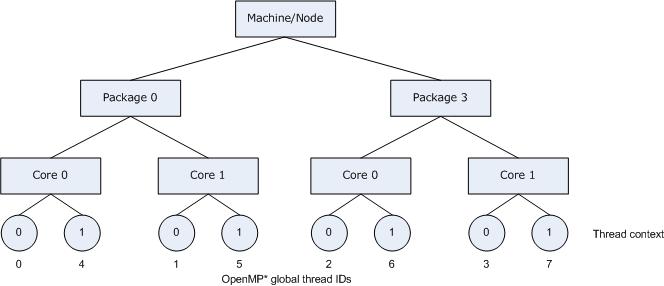
The OpenMP thread <n>+1 is bound to a thread context as close as possible to OpenMP thread <n> on a different core. Once each core has been assigned one OpenMP thread, the subsequent OpenMP threads are assigned to the available cores in the same order, but they are assigned on the unbound thread contexts.
logical and physical are deprecated; both are supported for backward compatibility. Use compact or scatter instead. For logical and physical affinity types, a single trailing integer is interpreted as an offset specifier instead of a permute specifier. In contrast, with compact and scatter types, a single trailing integer is interpreted as a permute specifier.
Assigns OpenMP threads to consecutive logical processors, which are also called hardware thread contexts. The type is equivalent to compact, except that the permute specifier is not allowed.
Assigns OpenMP threads to consecutive physical processors, for example, cores. For systems where there is only a single thread context per core, the type is equivalent to logical. For systems where multiple thread contexts exist per core, physical is equivalent to compact with a permute specifier of 1. This equivalence means that when the compiler sorts the map it should permute the innermost level of the machine topology map to the outermost, presumably the thread context level. This type does not support the permute specifier.
Modifiers are optional arguments that precede type. If you do not specify a modifier, the noverbose, respect, and granularity=core modifiers are used automatically.
Modifiers are interpreted in order from left to right, and can negate each other.
Does not print verbose messages.
Prints messages concerning the supported affinity. The messages include information about the number of packages, number of cores in each package, number of thread contexts for each core, and OpenMP thread bindings to physical thread contexts.
Information about binding OpenMP threads to physical thread contexts is indirectly shown in the form of the mappings between hardware thread contexts and the operating thread IDs. The affinity mask for each OpenMP thread is printed as a set of operating system processor IDs.
For example, specifying KMP_AFFINITY=verbose,scatter on a dual-core system with two processors, with HT Technology disabled, results in a message listing similar to the following:
Verbose, scatter message |
|---|
|
... KMP_AFFINITY: Affinity capable, using global cpuid info KMP_AFFINITY: Initial OS proc set respected: {0,1,2,3} KMP_AFFINITY: 4 available OS procs - Uniform topology of KMP_AFFINITY: 2 packages x 2 cores/pkg x 1 threads/core (4 total cores) KMP_AFFINITY: OS proc to physical thread map ([] => level not in map): KMP_AFFINITY: OS proc 0 maps to package 0 core 0 [thread 0] KMP_AFFINITY: OS proc 2 maps to package 0 core 1 [thread 0] KMP_AFFINITY: OS proc 1 maps to package 3 core 0 [thread 0] KMP_AFFINITY: OS proc 3 maps to package 3 core 1 [thread 0] KMP_AFFINITY: Internal thread 0 bound to OS proc set {0} KMP_AFFINITY: Internal thread 2 bound to OS proc set {2} KMP_AFFINITY: Internal thread 3 bound to OS proc set {3} KMP_AFFINITY: Internal thread 1 bound to OS proc set {1} |
The verbose modifier generates several standard, general messages. The following table summarizes how to read the messages.
Message String |
Description |
|---|---|
|
"affinity capable" |
Indicates that all components (compiler, operating system, and hardware) support affinity, so thread binding is possible. |
|
"using global cpuid info" |
Indicates that the machine topology was discovered by binding a thread to each operating system processor and decoding the output of the cpuid instruction. |
|
"using local cpuid info" |
Indicates that compiler is decoding the output of the cpuid instruction, issued by only the initial thread, and is assuming a machine topology using the number of operating system processors. |
|
"using /proc/cpuinfo" |
Linux* only. Indicates that cpuinfo is being used to determine system topology. |
|
"flat" |
Operating system processor ID is assumed to be equivalent to physical package ID. This method of determining system topology is used if none of the other methods will work, but may not accurately detect the actual machine topology. |
|
"uniform topology of" |
The system topology map is a full tree with no missing leaves at any level. |
The mapping from the operating system processors to package, core, and thread thread context ID is printed next. The binding of OpenMP thread thread context ID is printed next unless the affinity type is none. The thread level is contained in brackets (in the listing shown above). This implies that there is no representation of the thread context level in the machine topology map.
Binding OpenMP threads to particular packages and cores will often result in a performance gain on systems with Intel processors with HT Technology enabled; however, it is usually not beneficial to bind each OpenMP thread to a particular thread context on a specific core. Granularity describes the lowest levels that OpenMP threads are allowed to float within a topology map.
This modifier supports the following additional specifiers.
Specifier |
Description |
|---|---|
|
core |
Default. Broadest granularity level supported. Allows all the OpenMP threads bound to a core to float between the different thread contexts. |
|
fine or thread |
The finest granularity level. Causes each OpenMP thread to be bound to a single thread context. The two specifiers are functionally equivalent. |
Specifying KMP_AFFINITY=verbose,granularity=core,compact on the same dual-core system with two processors as in the previous section, but with HT Technology enabled, results in a message listing similar to the following:
Verbose, granularity=core,compact message |
|---|
|
KMP_AFFINITY: Affinity capable, using global cpuid info KMP_AFFINITY: Initial OS proc set respected: {0,1,2,3,4,5,6,7} KMP_AFFINITY: 8 available OS procs - Uniform topology of KMP_AFFINITY: 2 packages x 2 cores/pkg x 2 threads/core (4 total cores) KMP_AFFINITY: OS proc to physical thread map ([] => level not in map): KMP_AFFINITY: OS proc 0 maps to package 0 core 0 thread 0 KMP_AFFINITY: OS proc 4 maps to package 0 core 0 thread 1 KMP_AFFINITY: OS proc 2 maps to package 0 core 1 thread 0 KMP_AFFINITY: OS proc 6 maps to package 0 core 1 thread 1 KMP_AFFINITY: OS proc 1 maps to package 3 core 0 thread 0 KMP_AFFINITY: OS proc 5 maps to package 3 core 0 thread 1 KMP_AFFINITY: OS proc 3 maps to package 3 core 1 thread 0 KMP_AFFINITY: OS proc 7 maps to package 3 core 1 thread 1 KMP_AFFINITY: Internal thread 0 bound to OS proc set {0,4} KMP_AFFINITY: Internal thread 1 bound to OS proc set {0,4} KMP_AFFINITY: Internal thread 2 bound to OS proc set {2,6} KMP_AFFINITY: Internal thread 3 bound to OS proc set {2,6} KMP_AFFINITY: Internal thread 4 bound to OS proc set {1,5} KMP_AFFINITY: Internal thread 5 bound to OS proc set {1,5} KMP_AFFINITY: Internal thread 6 bound to OS proc set {3,7} KMP_AFFINITY: Internal thread 7 bound to OS proc set {3,7} |
The affinity mask for each OpenMP thread is shown in the listing (above) as the set of operating system processor to which the OpenMP thread is bound.
The following figure illustrates the machine topology map, for the above listing, with OpenMP thread bindings.
In contrast, specifying KMP_AFFINITY=verbose,granularity=fine,compact or KMP_AFFINITY=verbose,granularity=thread,compact binds each OpenMP thread to a single hardware thread context.
The behavior on Linux and Windows* is different.
Windows: Respect original affinity mask for the process.
Linux: Respect the affinity mask for the thread that initializes the OpenMP run-time library.
Specifying KMP_AFFINITY=verbose,compact for the same system used in the previous example, with HT Technology enabled, and invoking the library with an initial affinity mask of {4,5,6,7} (thread context 1 on every core) causes the compiler to model the system as a dual-core, two-processor system with HT Technology disabled.
Verbose,compact message |
|---|
|
KMP_AFFINITY: Affinity capable, using global cpuid info KMP_AFFINITY: Initial OS proc set respected: {4,5,6,7} KMP_AFFINITY: 4 available OS procs - Uniform topology of KMP_AFFINITY: 2 packages x 2 cores/pkg x 1 threads/core (4 total cores) KMP_AFFINITY: OS proc to physical thread map ([] => level not in map): KMP_AFFINITY: OS proc 4 maps to package 0 core 0 [thread 1] KMP_AFFINITY: OS proc 6 maps to package 0 core 1 [thread 1] KMP_AFFINITY: OS proc 5 maps to package 3 core 0 [thread 1] KMP_AFFINITY: OS proc 7 maps to package 3 core 1 [thread 1] KMP_AFFINITY: Internal thread 0 bound to OS proc set {4} KMP_AFFINITY: Internal thread 1 bound to OS proc set {6} KMP_AFFINITY: Internal thread 2 bound to OS proc set {5} KMP_AFFINITY: Internal thread 3 bound to OS proc set {7} KMP_AFFINITY: Internal thread 4 bound to OS proc set {4} KMP_AFFINITY: Internal thread 5 bound to OS proc set {6} KMP_AFFINITY: Internal thread 6 bound to OS proc set {5} KMP_AFFINITY: Internal thread 7 bound to OS proc set {7} |
Because there are eight thread contexts on the system, by default the compiler created eight threads for an OpenMP parallel construct.
The brackets around thread 1 indicate that the thread context level is ignored, and is not present in the topology map. The following figures illustrates the corresponding system topology map.
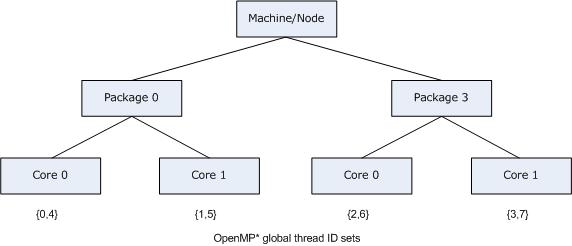
When using the local cpuid information to determine the machine topology, it is not always possible to distinguish between a machine that does not support Hyper-Threading Technology and a machine that supports it, but has it disabled. Therefore, the compiler does not include a level in the map if the elements (nodes) at that level had no siblings, with the exception that the package level is always modeled. As mentioned earlier, the package level will always appear in the topology map, even if there only a single package in the system.
Do not respect original affinity mask for the process. Binds OpenMP threads to all operating system processors.
In early versions of the OpenMP run-time library that supported only the physical and logical affinity types, norespect was the default and was not recognized as a modifier.
The default was changed to respect when types compact and scatter were added; therefore, thread bindings for the logical and physical affinity types may have changed with the newer compilers in situations where the application specified a partial initial thread affinity mask.