




![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) we restored missing data
by adopting the philosopy of minimizing the energy in filtered output.
In this chapter we learned about an optimum filter
for this task, the prediction-error filter (PEF).
Let us name this method the ``minimum noise'' method
of finding missing data.
we restored missing data
by adopting the philosopy of minimizing the energy in filtered output.
In this chapter we learned about an optimum filter
for this task, the prediction-error filter (PEF).
Let us name this method the ``minimum noise'' method
of finding missing data.
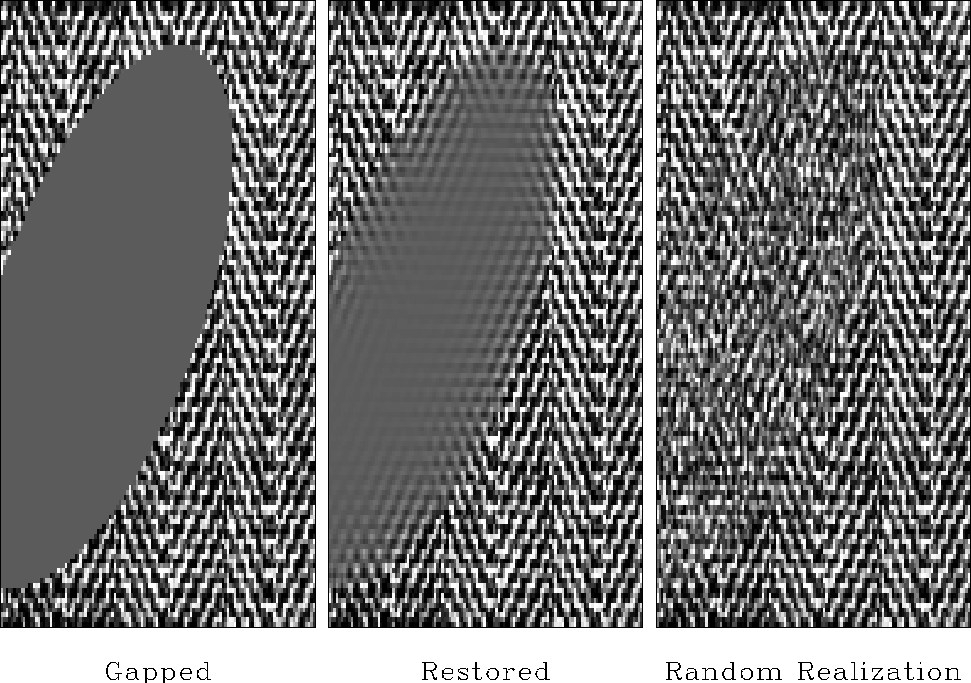
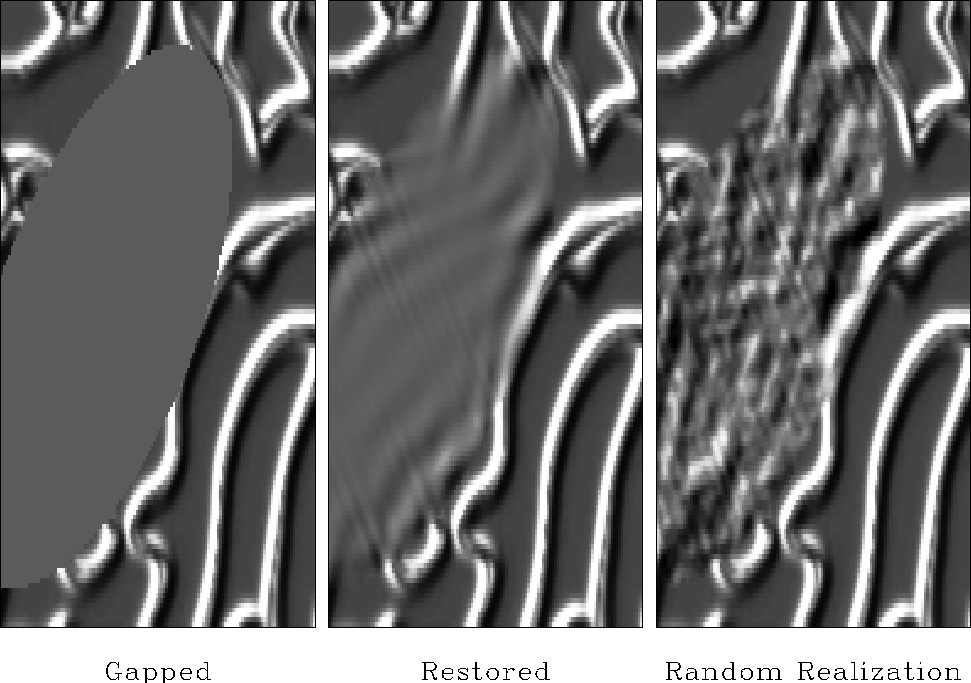
A practical problem with the minimum-noise method is evident
in a large empty hole such as
in Figures -
.
In such a void the interpolated data diminishes greatly.
Thus we have not totally succeeded in the goal of
``hiding our data acquisition footprint''
which we would like to do if we are trying to make
pictures of the earth and not pictures of our
data acquisition footprint.
What we will do next is useful in some applications but not in others.
Misunderstood or misused it is rightly controversial.
We are going to fill the empty holes
with something that looks like the original data but really isn't.
I will distinguish the words ``synthetic data''
(that derived from a physical model)
from ``simulated data'' (that manufactured from a statistical model).
We will fill the empty holes with simulated data
like what you see in the center panels of Figures
-.
We will add just enough of that ``wall paper noise'' to keep
the variance constant as we move into the void.
Given some data ![]() , we use it in a filter operator
, we use it in a filter operator ![]() ,and as described with equation (27) we build
a weighting function
,and as described with equation (27) we build
a weighting function ![]() that throws out the
broken regression equations (ones that involve missing inputs).
Then we find a PEF
that throws out the
broken regression equations (ones that involve missing inputs).
Then we find a PEF ![]() by using this regression.
by using this regression.
| (29) |
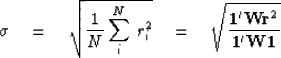 |
(30) |
| |
(31) |
keeping in mind that known data is constrained
(as detailed in chapter ).
To understand why this works,
consider first the training image, a region of known data.
Although we might think that the data defines the white noise
residual by ![]() , we can also imagine that the white noise
determines the data by
, we can also imagine that the white noise
determines the data by ![]() .Then consider a region of wholly missing data. This data
is determined by
.Then consider a region of wholly missing data. This data
is determined by ![]() .Since we want the data variance to be the same in known and unknown
locations, naturally we require the variance of
.Since we want the data variance to be the same in known and unknown
locations, naturally we require the variance of ![]() to match that of
to match that of ![]() .
.
A very minor issue remains.
Regression equations may have all of their required input data,
some of it, or none of it.
Should the ![]() vector add noise to every regression equation?
First, if a regression equation has all its input data
that means there are no free variables so it doesn't matter
if we add noise to that regression equation because the constraints
will overcome that noise.
I don't know if I should worry about how
many
inputs are missing for each regression equation.
vector add noise to every regression equation?
First, if a regression equation has all its input data
that means there are no free variables so it doesn't matter
if we add noise to that regression equation because the constraints
will overcome that noise.
I don't know if I should worry about how
many
inputs are missing for each regression equation.
It is fun making all this interesting ``wall paper''
noticing where it is successful and where it isn't.
We cannot help but notice that it seems to work better with
the genuine geophysical data than
it does with many of the highly structured patterns.
Geophysical data is expensive to acquire.
Regrettably, we have uncovered a technology
that makes counterfeiting much easier.
Examples are in Figures
-.
In the electronic book, the right-side panel of each figure is a movie,
each panel being derived from different random numbers.
 |
![[*]](http://sepwww.stanford.edu/latex2html/movie.gif)





 |
 |
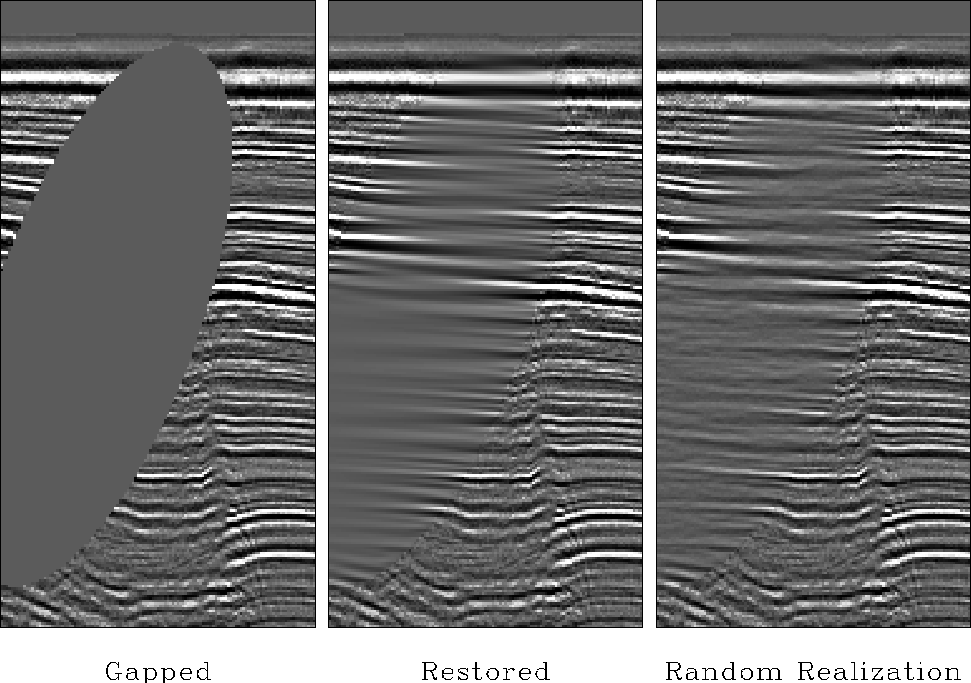 |
The seismic data in
Figure
illustrates a fundamental principle:
In the restored hole we do not see the same spectrum
as we do on the other panels.
This is because the hole is filled,
not with all frequencies (or all slopes) but with those
that are most predictable.
The filled hole is devoid of the unpredictable noise
that is a part of all real data.