




Next: Future Work
Up: Rickett, et al.: STANFORD
Previous: Applying PEFs to Fill
It is the purpose of the regularization parameter,  , to weight the regularization residual so that the iterative solver does not focus on one goal while ignoring the other. For example, an that is too large will insure that the missing data is filled but it may be too smooth. On the other hand, an that is too small will not fill in much data and will tend to leave the acquisition footprint behind.
, to weight the regularization residual so that the iterative solver does not focus on one goal while ignoring the other. For example, an that is too large will insure that the missing data is filled but it may be too smooth. On the other hand, an that is too small will not fill in much data and will tend to leave the acquisition footprint behind.
is used in fitting goal (2) to balance the two goals. For now, I applied Jon Claerbout's idea . Within the conjugate solver routine, the gradient determines in which direction to minimize the residual.
| 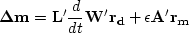 |
(115) |
Finding an which balances both goals we try:
| 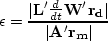 |
(116) |
In initial tests, I placed these equations in the solver and calculated a new for each iteration with the first value equal to 1. After about 15 iterations it converged to an almost constant value. This calculated was slightly lower than the that I found by trial and error. Figure ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) was generated using an of 0.4 whereas the calculated for that figure, returned by the above equation, was approximately 0.3.
was generated using an of 0.4 whereas the calculated for that figure, returned by the above equation, was approximately 0.3.
The calculated does not seem to work on the entire merged data set probably as a result of different data densities. The northern sparsely sampled region needs a different than the southern densely sampled region. In this case, a scalar value is not sufficient.
Next: Future Work
Up: Rickett, et al.: STANFORD
Previous: Applying PEFs to Fill
Stanford Exploration Project
7/5/1998