




|
data
Figure 1 The input data are irregularly sampled. | 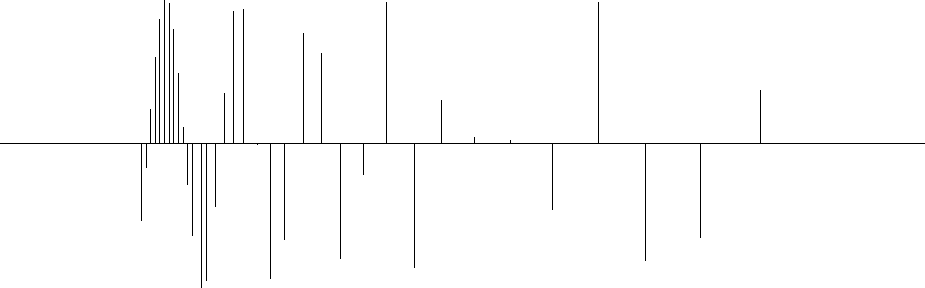 |





The first example is a simple synthetic test for 1-D inverse interpolation. The input data were randomly subsampled (with decreasing density) from a sinusoid (Figure 1). The forward operator L in this case is linear interpolation. We seek a regularly sampled model that could predict the data with a forward linear interpolation. Sparse irregular distribution of the input data makes the regularization enforcement a necessity. Following Claerbout, I applied convolution with the simple (1,-1) difference filter as the operator D that forces model continuity (the first-order spline). An appropriate preconditioner P in this case is recursive causal integration. Figures 2 and 3 show the results of inverse interpolation after exhaustive 300 iterations of the conjugate-direction method. The results from the model-space and data-space regularization look similar except for the boundary conditions outside the data range. As a result of using the causal integration for preconditioning, the rightmost part of the model in the data-space case stays at a constant level instead of decreasing to zero. If we specifically wanted a zero-value boundary condition, it wouldn't be difficult to implement it by adding a zero-value data point at the boundary.
|
im1
Figure 2 Estimation of a continuous function by the model-space regularization. The difference operator D is the derivative operator (convolution with (1,-1)). | 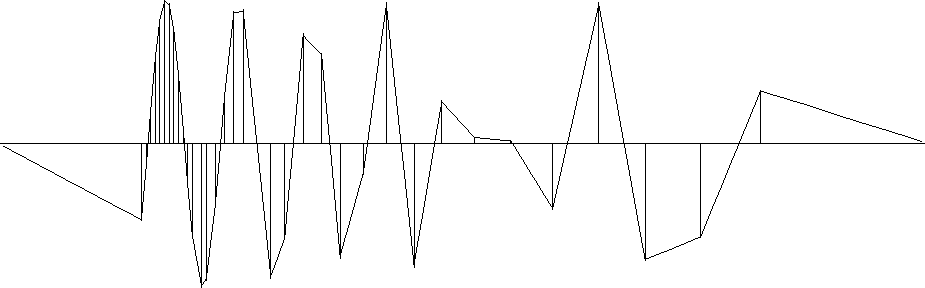 |
|
fm1
Figure 3 Estimation of a continuous function by the data-space regularization. The preconditioning operator P is causal integration. | 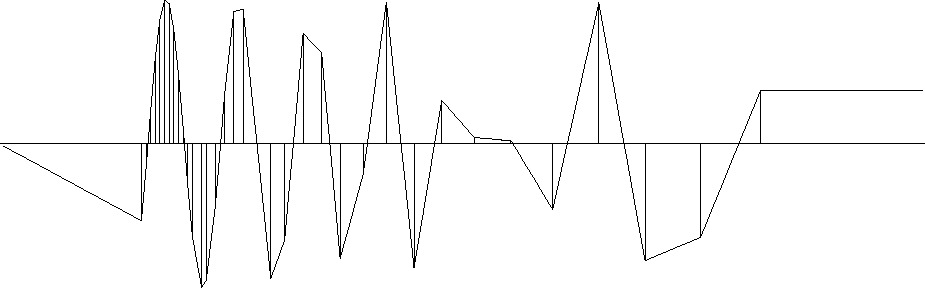 |
As expected from the general theory, the data-space regularization provides a much faster rate of convergence. Following Matthias Schwab's suggestion, I measured the rate of convergence by the model residual, which is a distance from the current model to the final solution. Figure 5 shows that the data regularization method converged to the final solution in about 6 times fewer iterations than the model regularization. Since the cost of each iteration for each method is roughly equal, the computational economy should be evident. Figure 4 shows the final solution, and the estimates from model- and data-space regularization after only 5 iterations of conjugate directions. The data-space estimate looks much closer to the final solution than its competitor.
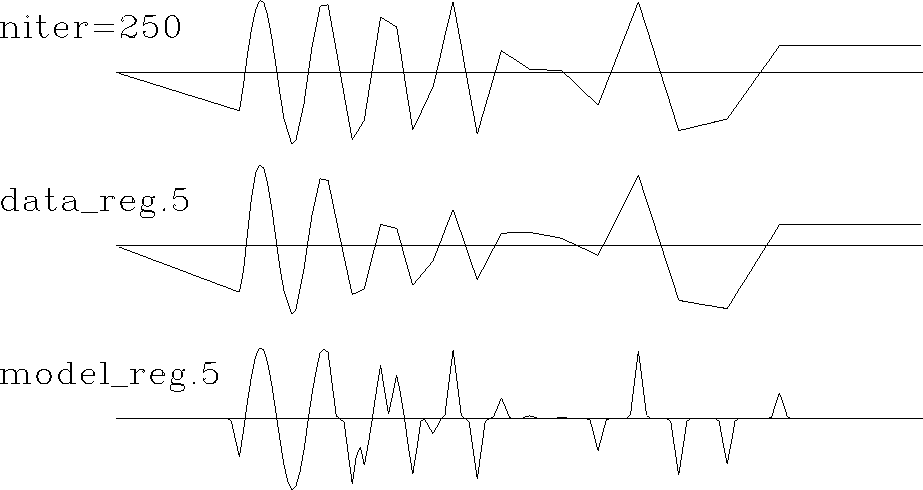 |
|
schwab1
Figure 5 Convergence of the iterative optimization, measured in terms of the model residual. The ``d'' points stand for data-space regularization; the ``m'' points, model-space regularization. | 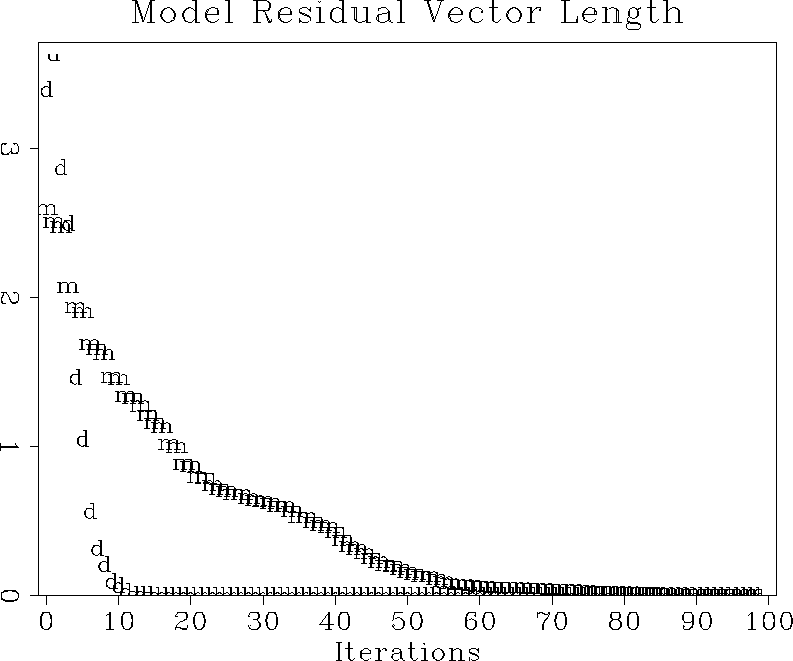 |
Changing the preconditioning operator changes the regularization result. Figure 6 shows the result of data-space regularization after applying a triangle smoother as the model preconditioner.
|
fm6
Figure 6 Estimation of a smooth function by the data-space regularization. The preconditioning operator P is a triangle smoother. | 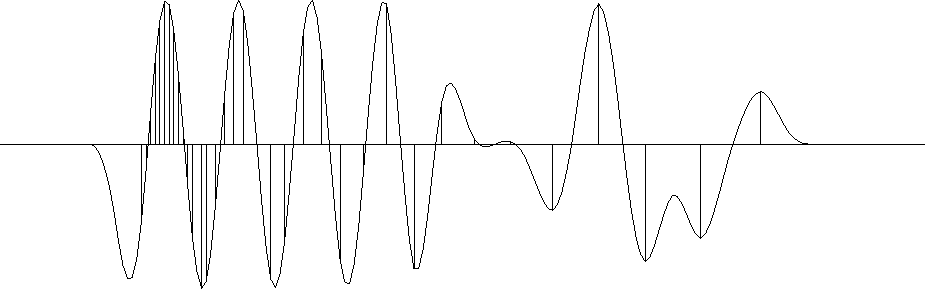 |
If, instead of looking for a smooth interpolation, we want to limit the number of frequency components, then the best choice for the model-space regularization operator D is a prediction-error filter (PEF). To obtain a mono-frequency output, we need to use a three-point PEF, which has the Z-transform representation D (Z) = 1 + a1 Z + a2 Z2. In this case, the corresponding preconditioner P could be the three-point recursive filter P (Z) = 1 / (1 + a1 Z + a2 Z2). To test this idea, I estimated the PEF D (Z) from the output of inverse linear interpolation (Figure 3), and ran the data-space regularized estimation again, substituting the recursive filter P (Z) = 1/ D(Z) in place of the causal integration. I repeated this two-step procedure three times to get a better estimate for the PEF. The result, shown in Figure 7, exhibits the desired mono-frequency output.
|
pm1
Figure 7 Estimation of a mono-frequency function by the data-space regularization. The preconditioning operator P is a recursive filter (the inverse of PEF). | 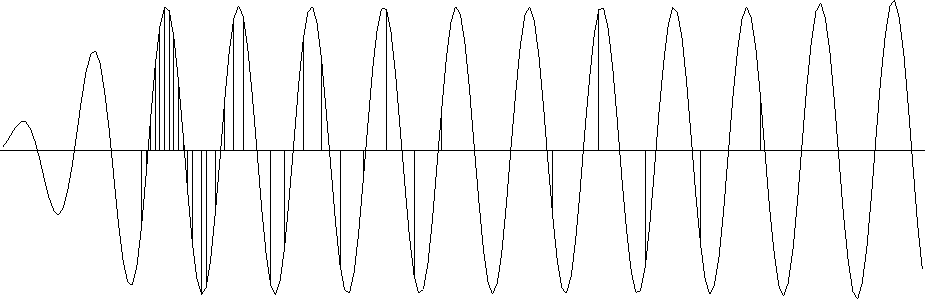 |