

![[*]](http://sepwww.stanford.edu/latex2html/prev_gr.gif)


Dave Nichols
dave@sep.stanford.edu
WHAT IS A NULL SPACE?
In many situations in geophysics we seek a solution to a problem of the form
![]()
![]()
![]()
The SVD explanation
The properties of the null space can be explored by examining the singular value decomposition of the operator. The SVD of B is given by
![]()
An important property of the adjoint operator ![]() is
that, when applied to any vector, it will always produce an output that
has no component in the null space. This is easily shown by
considering the SVD of
is
that, when applied to any vector, it will always produce an output that
has no component in the null space. This is easily shown by
considering the SVD of ![]() . The data vector
. The data vector ![]() can be
written as a linear combination of the basis vectors in the data
space.
can be
written as a linear combination of the basis vectors in the data
space.
![]()
![]()
An example problem
Consider the trivial under-determined problem
![]()
The first vector with singular value of one is,
![]()
![]()
One possible solution to the problem is made purely of the first vector,
![]()
An arbitrary amount of the second vector can be added to the solution
![]()
MINIMUM LENGTH SOLUTIONS AND ITERATIVE SOLVERS
The minimum length solution is the the solution with no null space component. These solutions are prefered by some people because they contain no information about the solution that is not a linear function of the data.
Any solution created by an iterative solver can be expressed in terms of a series expansion:
![]()
![]()
Since the last operation in each component of this solution is always the adjoint operator, we can immediately see that this type of solver will never add any information to the null space. If the initial solution is zero, then the final solution will have no component in the null space and it will be the minimum length solution.
Iterative solution of the model problem
The model problem is solved in one iteration by almost any algorithm since the operator is of rank one. I will illustrate the properties of the solution using a steepest descent algorithm. The first step applies the adjoint operator to the residual to get a gradient vector. Assuming an initial solution of zero, the residual is the same as the data.
![]()
![]()
![]()
![]()
The answer may be different if the initial solution is not zero. If the initial solution has energy in the null space, then that energy will remain in the final solution. An initial solution chosen arbitrarily is,
![]()
This initial solution has half its energy in the null space. Since this solution has a residual of zero, it is the final solution as well.
LEFT PRECONDITIONERS
Many methods for solving this problem introduce a premultiplying operator to the problem
![]()
This operator has different interpretations:
However, whatever the derivation, it does not change the fact that an
iterative solver will put no new energy in the null space of the model.
The adjoint operation is ![]() . The last
operator applied is
. The last
operator applied is ![]() so there is no null space energy
in the result.
so there is no null space energy
in the result.
RIGHT PRECONDITIONERS
In contrast a right preconditioner can change the energy in the null space of the solution. Now the problem to be solved is,
![]()
![]()
Again there are many reasons given for using this type of operator
When the adjoint of this operator is applied it may produce energy in
the null space of ![]() . The adjoint operation is
. The adjoint operation is ![]() . When this operator is used in an
iterative solver the solution will have no energy in the null space of
the composite operator
. When this operator is used in an
iterative solver the solution will have no energy in the null space of
the composite operator ![]() . The length that is
minimized is the norm of the solution in the transformed space, not the
norm in the original space.
. The length that is
minimized is the norm of the solution in the transformed space, not the
norm in the original space.
![]()
Right preconditioning of the example problem
The example problem can be solved with a diagonal right preconditioner. For no particular reason I have decided that I prefer to have more energy in the first unknown so I choose the preconditioner
![]()
![]()
![]()
![]()
![]()
MODEL PENALTY FUNCTIONS
An alternative strategy for dealing with the null space is to augment
the problem with a model penalty operator, ![]() .
.
We now seek the solution to the problem
![]()
![]()
![]()
Tarantola views these penalty as ``inverse model covariance operators''. I view them more generally; they describe something that I don't like about the model (e.g. roughness, smoothness, curvature, energy in one dip) that I want to minimize. Claerbout would like to estimate PEF's to use as penalty operators at the same time as he estimates the solution to the problem.
The sample problem with a model penalty operator
I can choose a simple penalty function that will minimize the energy in the second unknown
![]()
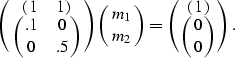
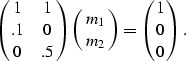
![]()
DISCUSSION
What is the best thing to do? I'm not sure. A good initial guess is obviously a good thing to have, but you had better be sure that you like the null-space component of your initial guess, as it isn't going to change.
The preconditioning approach has the attractive feature that you don't need to choose a scale factor. It has the limitation that the preconditioner must be full rank; you must not remove possible energy from the model.
The penalty function approach is much more general. It allows you to use any operator as a penalty function, but you have the added burden of choosing a good scale factor for that function.