The coordinate and boundary information is no longer
needed, once the operator has been constructed and boundary conditions have
been applied. All that remains is to solve the system of linear equations.
This can be efficiently done by the CG method. The CM code for the
iterations of the CG algorithm is almost a one-to-one match with the
algorithm outline given in Equation 1. This is one of the
more attractive features of CM-Fortran, there is none of the extra
clutter of do loops to obscure the meaning of the code.
Figure ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) shows the conjugate gradient loop in its entirety.
shows the conjugate gradient loop in its entirety.
DO WHILE( NORMRATIO > ERRLIM )
C Distribute the step information to all the nodes. CALL DISTRIBUTE( STEP, LOCSTEP, NNODEX, NNODEY )
C apply the operator CONJSTEP = 0. DO I =1,9 CONJSTEP = CONJSTEP + OPERATOR(I,:,:) * LOCSTEP(I,:,:) END DO
C calculate alpha ALPHA = PREVNORM / SUM( STEP * CONJSTEP )
C update soln SOLN = SOLN + ALPHA * STEP
C update residuals RESID = RESID - ALPHA * CONJSTEP
C calculate norm of residuals and beta RESIDNORM = SUM( RESID*RESID ) BETA = RESIDNORM/PREVNORM
C update the step STEP = RESID + BETA * STEP
C calculate relative error in residuals. NORMRATIO = RESIDNORM/RHSNORM
PREVNORM = RESIDNORM
END DO
The layout of the arrays and the coding of the distribution routine
depend on the connectivity of the nodes. In the model problem the
nodes can be mapped to a 2-D array and the distribution can be
performed as a series of shift operations. Figure shows
the CM code to define the array layout and Figure the
routine ``DISTRIBUTE''.
REAL OPERATOR(9,NNODEX,NNODEY) REAL LOCSTEP(9,NNODEX,NNODEY) CMF$LAYOUT OPERATOR(:SERIAL,:NEWS,:NEWS) CMF$LAYOUT LOCSTEP(:SERIAL,:NEWS,:NEWS)
REAL SOLN(NNODEX,NNODEY) REAL STEP(NNODEX,NNODEY) REAL RESID(NNODEX,NNODEY) REAL CONJSTEP(NNODEX,NNODEY) CMF$LAYOUT SOLN(:NEWS,:NEWS) CMF$LAYOUT RESID(:NEWS,:NEWS) CMF$LAYOUT STEP(:NEWS,:NEWS) CMF$LAYOUT CONJSTEP(:NEWS,:NEWS)
SUBROUTINE DISTRIBUTE( INPUT, OUTPUT, NNODEX, NNODEY )
C Gather information from all connected nodes. C This can be done with shift operations. C INTEGER NNODEX, NNODEY
REAL OUTPUT(9,NNODEX,NNODEY) CMF$LAYOUT OUTPUT(:SERIAL,:NEWS,:NEWS)
REAL INPUT(NNODEX,NNODEY) CMF$LAYOUT INPUT(:NEWS,:NEWS)
OUTPUT(5,:,:) = INPUT
OUTPUT(4,:,:) = CSHIFT( OUTPUT(5,:,:), DIM=1, SHIFT=-1 ) OUTPUT(1,:,:) = CSHIFT( OUTPUT(4,:,:), DIM=2, SHIFT=-1 ) OUTPUT(7,:,:) = CSHIFT( OUTPUT(4,:,:), DIM=2, SHIFT=1 )
OUTPUT(6,:,:) = CSHIFT( OUTPUT(5,:,:), DIM=1, SHIFT=1 ) OUTPUT(3,:,:) = CSHIFT( OUTPUT(6,:,:), DIM=2, SHIFT=-1 ) OUTPUT(9,:,:) = CSHIFT( OUTPUT(6,:,:), DIM=2, SHIFT=1 )
OUTPUT(2,:,:) = CSHIFT( OUTPUT(5,:,:), DIM=2, SHIFT=-1 ) OUTPUT(8,:,:) = CSHIFT( OUTPUT(5,:,:), DIM=2, SHIFT=1 )
RETURN END
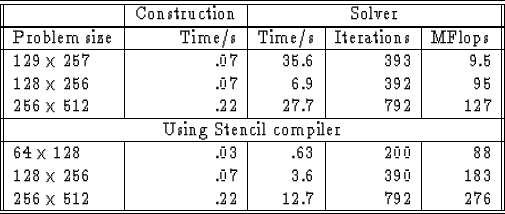
Table 7 shows the timings for the model problem. The first
set of figures is for the code given in Figure . The
second set of figures is for a version of the code in which the
distribution and application steps were replaced by a call to a
routine compiled with the stencil compiler. This is a special purpose
compiler for compiling algorithms that can be coded as a stencil
operation. Biondo Biondi used a pre-release version of this compiler
to create the routine that I used.
There are several points to note: