




Next: Estimating the factors of
Up: CLASH IN PHILOSOPHIES
Previous: Relying on interpolated data?
Perhaps we should consider the
rate of convergence of the optimization method.
Glass will turn to crystal if you wait long enough.
But we never can wait long enough.
Inversion methods are notorious for slow convergence.
Consider that matrix inversion costs are proportional
to the cube of the number of unknowns;
our most powerful computers balk
when the number of unknowns goes above the mid hundreds;
and our images generally have millions.
Perhaps the crystal quartz analogy is not far fetched.
The question is whether explicitly including the missing data
slows things down by adding more unknowns and complexity,
or whether it can speed things up.
Matrix inversion by iterative methods amounts to
iterative application of an operator and its conjugate.
Given 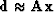 ,the solution
,the solution  is implicitly developed in a power series
is implicitly developed in a power series
| ![\begin{displaymath}
\bold x {=}\left[
\sum_n \alpha_n (\bold A' \bold A)^n
\right]
\bold A'\bold d\end{displaymath}](img27.gif) |
(6) |
where the 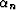 are implicitly determined by the numerical method
(such as steepest descent or conjugate gradients).
The operator
are implicitly determined by the numerical method
(such as steepest descent or conjugate gradients).
The operator 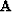 has the rows
has the rows 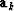 on top
and under those rows are optional rows of
on top
and under those rows are optional rows of 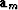 and under that are the optional stabizing rows of
and under that are the optional stabizing rows of 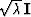 .Why should convergence be faster when
the matrix includes missing data rows?
I'll suggest that when the data space is completed
(made large enough to fully determine the solution)
then the conjugate operator
.Why should convergence be faster when
the matrix includes missing data rows?
I'll suggest that when the data space is completed
(made large enough to fully determine the solution)
then the conjugate operator 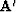 has a better chance
of being close to the inverse operator.
Many of our data processing procedures
are so huge that we do little more
than apply the conjugate operator,
and the conjugate to the missing-data-extended operator
is better than the conjugate to the data-truncated operator.
has a better chance
of being close to the inverse operator.
Many of our data processing procedures
are so huge that we do little more
than apply the conjugate operator,
and the conjugate to the missing-data-extended operator
is better than the conjugate to the data-truncated operator.
Next: Estimating the factors of
Up: CLASH IN PHILOSOPHIES
Previous: Relying on interpolated data?
Stanford Exploration Project
1/13/1998