 |
 |
 |
 | Alternatives to conjugate direction optimization for sparse solutions to geophysical problems |  |
![[pdf]](icons/pdf.png) |
Next: Linear Programming
Up: Moussa: Alternative optimization schemes
Previous: Introduction
Early work focused on a pure conjugate-gradient or steepest-descent method using the true 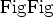 norm. We implemented a modified version of cg_step, implementing a line search first as a weighted median search, and also with a full, explicit calculation of the Frechet derivative. It was conclusively shown that the gradient of a pure solution resulted in introduction of local minima, resulting in a failure to converge. This has been noted in prior work (Bube and Langan, 1997) - the pure norm is not strictly convex. This can be shown with the trivial example of finding the minimum for a median problem with even number of elements:
norm. We implemented a modified version of cg_step, implementing a line search first as a weighted median search, and also with a full, explicit calculation of the Frechet derivative. It was conclusively shown that the gradient of a pure solution resulted in introduction of local minima, resulting in a failure to converge. This has been noted in prior work (Bube and Langan, 1997) - the pure norm is not strictly convex. This can be shown with the trivial example of finding the minimum for a median problem with even number of elements:
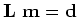 |
(1) |
The residual in the case is the sum
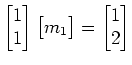 , which has nonunique global minima for all
, which has nonunique global minima for all
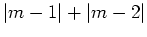 . The gradient, in this entire region, is exactly zero. In a larger, non-trivial data-fitting problem, these zero-value gradients can occur at locations other than the global optimum - and thus the gradient-based methods do not function properly.
. The gradient, in this entire region, is exactly zero. In a larger, non-trivial data-fitting problem, these zero-value gradients can occur at locations other than the global optimum - and thus the gradient-based methods do not function properly.
|
|
|
|
| Alternatives to conjugate direction optimization for sparse solutions to geophysical problems | |
|
Next: Linear Programming
Up: Moussa: Alternative optimization schemes
Previous: Introduction
2009-10-19