|
|
|
|
Seismic imaging using GPGPU accelerated reverse time migration |
For the purposes of this report, I will focus on single-GPU kernels. I made significant progress towards multi-GPU asynchronous parallelization, but this code is not yet ready to provide benchmark results. The eventual goal is to perform the forward-wave, reverse-wave, and imaging condition subroutines on independent GPUs. However, preliminary benchmark results cast doubt on whether that approach will decrease total execution time, because the bottleneck appears to be host-device transfer time rather than computational limitations.
Implementation of an eighth-order spatial derivative added negligible computational overhead to the problem, as compared to the naive second-order wave operator. This suggests that other more sophisticated time-stepping methods, such as Arbitrary Difference Precise Integration (ADPI) wave solvers (Lei Jia and Guo, 2008), may also have negligible computational overhead. Such methods will enable coarser time-steps without the numerical stability limitations that are inherent in FDTD approaches. Thus the use of those methods may reduce overall execution time.
|
|---|
|
hostDeviceMultiGPUschem
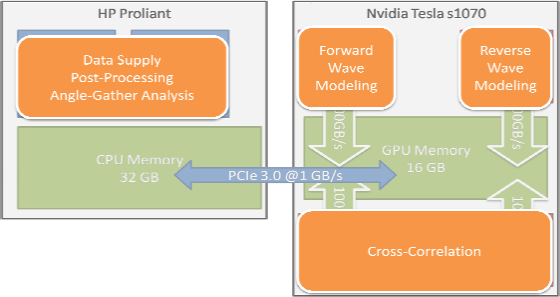
Figure 3. Schematic view of the multi-GPU algorithm for coarse-grained parallelism. The intent is to perform the overall RTM process with separate stages executing in parallel on independently controlled GPUs. This coarse parallelism can help pipeline the process and hide the memory transfer time. My current implementation and benchmark-code does not yet implement this strategy. [NR] |
|
|
The expansion of the solver to a full 3D model space will require significant extra programming. The code base for the 2D model is intended to be extensible, and the CUDA framework allows block indexing to subdivide a computational space into 3 dimensions, assigning an (X,Y,Z) coordinate to each block and each thread. Because of time constraints, I did not complete the full 3D modeling for benchmark comparison.
In the current iteration, the host code does not perform significant parallelism. Earlier efforts used pthread parallelism on the host CPUs for data preprocessing while the input loaded from disk, but the time saved by this workload parallelism was negligible compared to the overall execution time.
The result of my implementation is a propagation program, waveprop0, and an imaging program, imgcorr0, written in CUDA. These are piped together with a set of Unix shell scripts to manage the overall RTM sequence for forward and reverse-time propagation with an imaging condition.
Future implementations will seek to integrate these programs into one tool with several CUDA kernels, but the overlying data-dependence issue must be solved theoretically before the processes can be entirely converted to a streaming methodology. For trivial-sized problems, the entire computational result of forward and backward wave propagation can remain in graphics device memory for use, but this approach has inherent problem-size limitations. Other methods of eliminating the costly host-device transfers have been proposed (Clapp, 2009). Such methods eliminate the bottleneck by preserving the wavefield state in GPU memory at the final timestep, and backward-propagating to recompute the wavefield at arbitrary time. This takes advantage of the cheap and fast wave propagation kernel. Another approach is the effective pipelining of the RTM process to allow arbitrary-sized input data sets. Finally, a major area of continuing work is the complete linking of CUDA research code with the standard SEPlib programming environment and toolkit. This will be extremely beneficial from the standpoint of code portability and interoperability with other research areas.
|
|
|
|
Seismic imaging using GPGPU accelerated reverse time migration |