




Instead of adjusting the intensities of ![]() , the second algorithm synthesizes a new volume from a convex combination of the source volumes
, the second algorithm synthesizes a new volume from a convex combination of the source volumes ![]() and
and ![]() . The relative levels of contribution from
. The relative levels of contribution from ![]() and
and ![]() are determined by how much
are determined by how much ![]() deviates from
deviates from ![]() , where
, where ![]() is defined by Eq. 1 and is the intensity of the gray background in
is defined by Eq. 1 and is the intensity of the gray background in ![]() . Specifically, we form
. Specifically, we form
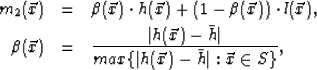 |
(3) | |
| (4) |
Here, in terms of the framework in Fig. 3, the upper branch's extraction of high-frequency components from ![]() and scaling depicted are contained in the term
and scaling depicted are contained in the term ![]() . Similarly, the lower branch's extraction of low-frequency components from
. Similarly, the lower branch's extraction of low-frequency components from ![]() and scaling are contained in the term
and scaling are contained in the term ![]() .
.
When combining the slices from Fig. 1, we obtained the synthesized result shown in Fig. 5. The advantage of the second algorithm is that it synthesizes the local structures from ![]() in the new volume more accurately than does the first algorithm, but this is done at the expense of sacrificing a small amount of textural smoothness inherited from
in the new volume more accurately than does the first algorithm, but this is done at the expense of sacrificing a small amount of textural smoothness inherited from ![]() . Again, the local means from
. Again, the local means from ![]() are well preserved.
are well preserved.
 |
