




| |
(1) |
Imagine that after solving equation (1), the data residuals consist of spikes separated by relatively large distances. Then the estimated time shifts ![]() would be piecewise smooth with jumps at the spike locations (fault locations), which is what we desire. However, in solving Equation (1), we use the least-squares criterion - minimization of the
would be piecewise smooth with jumps at the spike locations (fault locations), which is what we desire. However, in solving Equation (1), we use the least-squares criterion - minimization of the ![]() norm of the residual. Large spikes in the residual tend to be attenuated. In the model space, the solver smooths the time shifts across the spike location.
norm of the residual. Large spikes in the residual tend to be attenuated. In the model space, the solver smooths the time shifts across the spike location.
It is known that the ![]() norm is less sensitive to spikes in the residual Claerbout and Muir (1973); Darche (1989); Nichols (1994). Minimization of the
norm is less sensitive to spikes in the residual Claerbout and Muir (1973); Darche (1989); Nichols (1994). Minimization of the ![]() norm makes the assumption that the residuals are exponentially distributed and have a ``long-tailed'' distribution relative to the Gaussian function assumed by the
norm makes the assumption that the residuals are exponentially distributed and have a ``long-tailed'' distribution relative to the Gaussian function assumed by the ![]() norm inversion.
norm inversion.
|
2
Figure 1 Comparison of the loss functions for the | 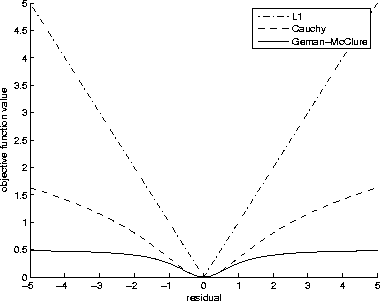 |





|
3
Figure 2 Comparison of weight functions for the | 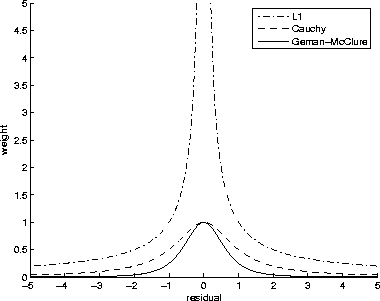 |
Here, we compute non-linear model residual weights which force a Geman-McClure distribution, another long-tailed distribution which approximates an exponential distribution. A comparison of the loss functions for the ![]() , Cauchy Claerbout (1999), and Geman-McClure functions is shown in Figure
, Cauchy Claerbout (1999), and Geman-McClure functions is shown in Figure ![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) . Notice that the Geman-McClure is the most robust in that it is the least sensitive to outliers. Our weighted regression now is the following over-determined system:
. Notice that the Geman-McClure is the most robust in that it is the least sensitive to outliers. Our weighted regression now is the following over-determined system:
| (2) |
Our method consists of recomputing the weights at each non-linear iteration, solving small piecewise Gauss-Newton linear problems. The IRLS algorithms converge if each minimization reaches a minimum for a constant weight. We perform the following non-linear iterations:
starting with the weights ![]() , at the jth iteration the algorithm solves
, at the jth iteration the algorithm solves
iterate {
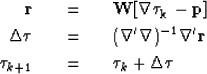 |
(3) | |
| (4) | ||
| (5) |
}At every non-linear iteration jth iteration we re-estimate our Geman-McClure weight function:
| |
(6) |
. Notice that the Geman-McClure creates the tightest, most precise weight. This should have the advantage of having a surgical-like effect of down-weighting spurious dips.