




The base parallel class SEP.pf_base.parfile inherits from both the SEP.sepfile.sep_file and the SEP.stat_sep.status classes. It is initialized with at least an ASCII description, name, the usage of the file usage ("INPUT" or "OUTPUT"), and the tag that the program uses to access it (e.g. <, data=, >). In addition, it must be either initialized with the list of tasks, mentioned above, or have its status loaded from disk using the load argument. In addition the user can specify
![[*]](http://sepwww.stanford.edu/latex2html/cross_ref_motif.gif) .
.
|
parfile
Figure 1 The inheritance chart for the parallel file objects. | 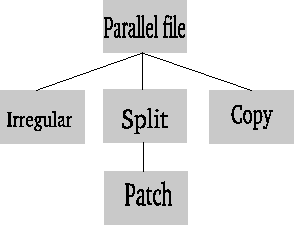 |

The class SEP.pf_copy.parfile is the simplest of the parallel files. It only works with a regular SEPlib cube. If the named file is an input file, SEP.pf_copy.parfile copies the entire file to each node. If the named file is an output file, n collection all of the local version will be summed to produce the final output. This class has the additional initialization argument reuse_par, which tells how to signify to the program that the file already exists. This argument is added to the returned parameters in tags when dealing with an output file that already exists. An example of a SEP.pf_copy.parfile is the velocity and image files in migration. The reuse_par argument would be needed when the image file is already created on the node, to signify that we need to add to rather than replace, the image. Transferring the data is done in megabyte-sized chunks from one node to the next to build up the image using Copy_join or to distribute using Copy_split.
The class SEP.pf_split.parfile allows a parallel file to be split along one or more axes. It is initialized with the additional parameter dff_axis, the axis or axes we are splitting along, and nblock, the number of portion that axis will be split into. An example of a SEP.pf_split.parfile file would be the frequencies in downward-continuation migration. The same principal is used to transfer the data. Megabyte-sized chunks are passed from one node to the next using Patch_split and Patch_join. When a node contains a given chunk, it is read from or written to disk, otherwise it just passes what it received.
The class SEP.pf_patch.parfile inherits from SEP.pf_split.parfile. It is used when overlapping patches of a dataset are needed. It adds the additional initialization argument noverlap, which tells how much overlap between the patches along each axis. An example would be the image space in shot-profile migration. When collecting, it applies a triangle in the overlapped region.
The last type of parallel file is the class SEP.pf_irreg.parfile. It currently can only be used as input. It is defined for irregular datasets (aka SEP3D). It has the ability to be split along multiple axes and have overlapping patches. It use Sep3d_split for distribution. The distribution is fairly smart. It does not attempt to sort the dataset but instead makes sure that each local version of the data contains an updated data_record_number. As a result, it can be a very effective method to handle large-sized sorts.